番茄工作法
这里有东西被加密了,需要输入密码查看哦。
Microsoft Graph API
What is Graph API
Graph API authentication
OAuth Authentication flows
Apps and authentication senarios
Call Graph API from Office Web Addin
Call via https://outlook.office.com/api
Call visa Office.js for Outlook REST API
Outlook REST API via outlook.office.com
Call via https://grsph.microsoft.com/
with Authentication with SSO token
Troubleshooting GetAccessToken
Other Option: use EWS call from Office.js
2021年度个人规划
这里有东西被加密了,需要输入密码查看哦。
Java NIO
Java异步计算方法与异步网络通信框架
Java异步方法
异步方法(Java asynchronized programming)是提升程序性能的一个有效手段,采用已经封装好的方法,让JVM去控制线程的创建和回收管理,减少了线程的阻塞,让程序员更加关注方法的设计。
Callable,Future, 和FutureTask
- Callable
Callable接口使用泛型去定义它的返回类型。Executors类提供了一些有用的方法去在线程池中执行Callable内的任务。由于Callable任务是并行的,必须等待它返回的结果。java.util.concurrent.Future对象解决了这个问题。
在线程池提交Callable任务后返回了一个Future对象,使用它可以知道Callable任务的状态和得到Callable返回的执行结果。Future提供了get()方法,等待Callable结束并获取它的执行结果。
Callable与Runnable接口很相似,不同之处在于一个需要返回值,一个不需要。而且Callable可以抛出异常。
- Future和FutureTask
FutureTask是Future接口的一个唯一实现类。
FutureTask类实现了RunnableFuture接口,RunnableFuture继承了Runnable接口和Future接口,所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
Future接口的不足:
Future接口可以构建异步应用,但依然有其局限性。它很难直接表述多个Future 结果之间的依赖性。实际开发中,我们经常需要达成以下目的:
* 将两个异步计算合并为一个——这两个异步计算之间相互独立,同时第二个又依赖于第一个的结果。
* 等待 Future 集合中的所有任务都完成。
* 仅等待 Future 集合中最快结束的任务完成(有可能因为它们试图通过不同的方式计算同一个值),并返回它的结果。
* 通过编程方式完成一个 Future 任务的执行(即以手工设定异步操作结果的方式)。
* 应对 Future 的完成事件(即当 Future 的完成事件发生时会收到通知,并能使用 Future计算的结果进行下一步的操作,不只是简单地阻塞等待操作的结果)
在CompletableFuture中,满足了上述的目的。
CompletableFuture
通过静态方法产生CompletableFuture实例。CompletableFuture的底层实现原理:
| 静态方法 | 内容 |
|---|---|
runAsync(Runnable runnable) |
使用ForkJoinPool.commonPool()作为它的线程池执行异步代码。 |
runAsync(Runnable runnable, Executor executor) |
使用指定的thread pool执行异步代码。 |
supplyAsync(Supplier<U> supplier) |
使用ForkJoinPool.commonPool()作为它的线程池执行异步代码,异步操作有返回值 |
supplyAsync(Supplier<U> supplier, Executor executor) |
使用指定的thread pool执行异步代码,异步操作有返回值 |
示例代码:
1 | // CompletableFuture 在调用runAsync后会立刻执行,定义的Runnable输入参入与.NET中定义的Task.Run(Action a)很相似。 |
底层是通过一个线程池接收提交的任务,源码是用一个Executor实例执行lamda表达式,一般默认是运用ForJoinPool线程池中的线程执行。
1 | private static final Executor ASYNC_POOL = USE_COMMON_POOL ? |
| 实例方法 | 内容 |
|---|---|
thenRun(Runnable runnable) |
可以传入一个Lamda表达式作为后续处理方法 |
thenAccept(Comsummer<? super T> consummer) |
在异步task执行完成后传入一个Action方法来处理输出参数,如果void输出是不需要thenAccept(**),也有async版本 |
thenApply(Function<? super T, ? super E> function) |
在异步task执行完成后传入一个Func来处理输出参数,并且得出返回值,也有async版本 |
thenCombine(CompletionStage<? extends U> taskToBeCombined, Function<? super T, ? super U> function) |
Task并联,两个都执行完成了再继续fucntion) |
thenCompose(Function<? extends U> function, CompletionStage<U> cf) |
Task串联,本task执行完成后再执行下一步 |
complete(T t) |
立刻返回Task的结果,并且返回值是t。当然如果Task已经异步执行完毕,则设置失效 |
completeExceptionally(Throwable x) |
立刻返回Task并且抛出对应的Exception。如果Task已经结束,则不变。 |
get() |
尝试获取结果,如果没有结束/抛出exception/cancel掉,都会抛出对应的exception. |
join() |
join()方法会阻塞当前线程,同步执行等待结果,和.NET的Task.wait()方法相似,如果有异常/被取消,会抛出相应的exception。 |
handle(BiFunction<? super T, Throwable, ? extends U> fn) |
将event handler传入,待到task执行完毕后进行处理/exception handling。也有async版本 |
exceptionally(Function<Throwable,? extends T> fn) |
为异步方法注册exception的callback,当然也可以给该task注册下一步的方法在thenApply(..)中。 |
- Lambda表达式
在Java里,lamda表达式的实质是函数。Runnable是一种特殊的lamda表达式,也就是.NET 中的Action类型委托实例,()-> { ….; return void;}
题外话: C#异步编程方法
C#异步编程框架依赖于CLR的实现,更加高效和简单明了,而Java的异步方法依赖线程池实现。
Java NIO网络编程框架
在网络编程领域,节点间式依赖TCP/UDP协议进行通信,Java提供的Socket实现在JDK 1.4以前是阻塞I/O, 也就是说每一个Socket连接,JVM中会分配一个线程阻塞等待连接建立,数据通信,在高并发场景下会发生线程池线程用尽的情况,为了优化网络通信效率,出现了非阻塞/异步I/O的设计方案。
Reactor模式设计思想
Netty通信框架的设计思想是基于Reactor模式思想,这是一种基于事件驱动的设计思想。能够高效的解决很多程序设计中的线程不必要阻塞问题。Java NIO也是基于Reactor设计思想实现的,在JVM本地方法层面做到了多路复用I/O。
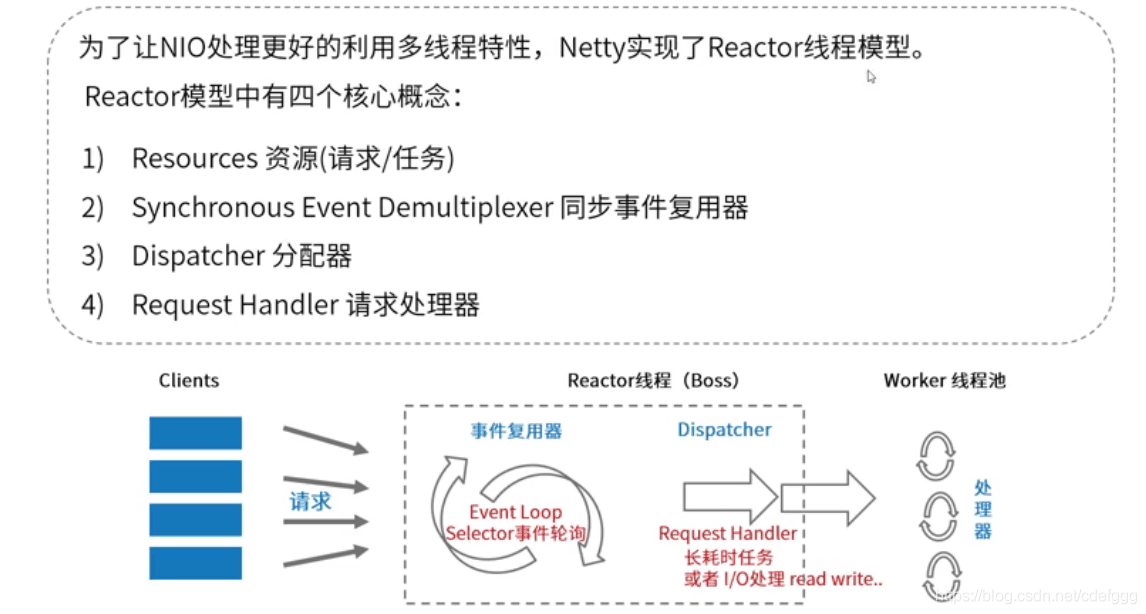
Reactor模式中的五个角色:
- Handle(句柄或描述符,在Windows下称为句柄,在Linux下称为描述符):
本质上表示一种资源(比如说文件描述符,或是针对网络编程中的socket描述符),是由操作系统提供的;该资源用于表示一个个的事件,事件既可以来自于外部,也可以来自于内部;外部事件比如说客户端的连接请求,客户端发送过来的数据等;内部事件比如说操作系统产生的定时事件等。它本质上就是一个文件描述符,Handle是事件产生的发源地。 - Synchronous Event Demultiplexer(同步事件分离器):
它本身是一个系统调用,用于等待事件的发生(事件可能是一个,也可能是多个)。调用方在调用它的时候会被阻塞,一直阻塞到同步事件分离器上有事件产生为止。对于Linux来说,同步事件分离器指的就是常用的I/O多路复用机制,比如说select、poll、epoll等。在Java NIO领域中,同步事件分离器对应的组件就是Selector;对应的阻塞方法就是select方法。 - Event Handler(事件处理器):
本身由多个回调方法构成,这些回调方法构成了与应用相关的对于某个事件的反馈机制。在Java NIO领域中并没有提供事件处理器机制让我们调用或去进行回调,是由我们自己编写代码完成的。Netty相比于Java NIO来说,在事件处理器这个角色上进行了一个升级,它为我们开发者提供了大量的回调方法,供我们在特定事件产生时实现相应的回调方法进行业务逻辑的处理,即,ChannelHandler。ChannelHandler中的方法对应的都是一个个事件的回调。 - Concrete Event Handler(具体事件处理器):
是事件处理器的实现。它本身实现了事件处理器所提供的各种回调方法,从而实现了特定于业务的逻辑。它本质上就是我们所编写的一个个的处理器实现。 - Initiation Dispatcher(初始分发器):
实际上就是Reactor角色。它本身定义了一些规范,这些规范用于控制事件的调度方式,同时又提供了应用进行事件处理器的注册、删除等设施。它本身是整个事件处理器的核心所在,Initiation Dispatcher会通过Synchronous Event Demultiplexer来等待事件的发生。一旦事件发生,Initiation Dispatcher首先会分离出每一个事件,然后调用事件处理器,最后调用相关的回调方法来处理这些事件。Netty中ChannelHandler里的一个个回调方法都是由bossGroup或workGroup中的某个EventLoop来调用的。
Reactor线程处理流程理解:
初始化Initiation Dispatcher,然后将若干个Concrete Event Handler注册到Initiation Dispatcher中。当应用向Initiation Dispatcher注册Concrete Event Handler时,会在注册的同时指定感兴趣的事件,即,应用会标识出该事件处理器希望Initiation Dispatcher在某些事件发生时向其发出通知,事件通过Handle来标识,而Concrete Event Handler又持有该Handle。这样,事件 ————> Handle ————> Concrete Event Handler 就关联起来了。
Initiation Dispatcher 会要求每个事件处理器向其传递内部的Handle。该Handle向操作系统标识了事件处理器。
当所有的Concrete Event Handler都注册完毕后,应用会调用handle_events方法来启动Initiation Dispatcher的事件循环。这是,Initiation Dispatcher会将每个注册的Concrete Event Handler的Handle合并起来,并使用Synchronous Event Demultiplexer(同步事件分离器)同步阻塞的等待事件的发生。比如说,TCP协议层会使用select同步事件分离器操作来等待客户端发送的数据到达连接的socket handler上。
比如,在Java中通过Selector的select()方法来实现这个同步阻塞等待事件发生的操作。在Linux操作系统下,select()的实现中:
会将已经注册到Initiation Dispatcher的事件调用epollCtl(epfd, opcode, fd, events)注册到linux系统中,这里fd表示Handle,events表示我们所感兴趣的Handle的事件;
通过调用epollWait方法同步阻塞的等待已经注册的事件的发生。不同事件源上的事件可能同时发生,一旦有事件被触发了,epollWait方法就会返回;
最后通过发生的事件找到相关联的SelectorKeyImpl对象,并设置其发生的事件为就绪状态,然后将SelectorKeyImpl放入selectedSet中。这样一来我们就可以通过Selector.selectedKeys()方法得到事件就绪的SelectorKeyImpl集合了。
当与某个事件源对应的Handle变为ready状态时(比如说,TCP socket变为等待读状态时),Synchronous Event Demultiplexer就会通知Initiation Dispatcher。
Initiation Dispatcher会触发事件处理器的回调方法,从而响应这个处于ready状态的Handle。当事件发生时,Initiation Dispatcher会将被事件源激活的Handle作为『key』来寻找并分发恰当的事件处理器回调方法。
Initiation Dispatcher会回调事件处理器的handle_event(type)回调方法来执行特定于应用的功能(开发者自己所编写的功能),从而相应这个事件。所发生的事件类型可以作为该方法参数并被该方法内部使用来执行额外的特定于服务的分离与分发。
Netty通信框架之NIO的源码分析
Netty服务器单线程Reactor处理模型源码分析
服务器端的Reactor是一个线程对象(EventLoopGroup),该线程会启动事件循环,并使用Selector来实现IO的多路复用。注册Channel通道(包含Acceptor事件处理器Selector)到Reactor中,Acceptor事件处理器所关注的事件是ACCEPT(IO)事件,这样Reactor会循环监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。
当客户端向服务器端发起一个连接请求,Reactor监听到了该ACCEPT事件的发生并将该ACCEPT事件派发给相应的Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将该连接所关注的READ(IO)事件以及对应的READ事件处理器注册到Reactor中,这样一来Reactor就会监听该连接的READ事件了。或者当你需要向客户端发送数据时,就向Reactor注册该连接的WRITE事件和其处理器。
当Reactor监听到有读或者写事件发生时,将相关的事件派发给对应的处理器(另一个EventLoopGroup工作循环线程组)进行处理。比如,读处理器会通过SocketChannel的read()方法读取数据,此时read()操作可以直接读取到数据,而不会堵塞与等待可读的数据到来。
每当处理完所有就绪的感兴趣的I/O事件后,Reactor线程会再次执行select()阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
注意,Reactor的单线程模式的单线程主要是针对于I/O操作而言,也就是所以的I/O的accept()、read()、write()以及connect()操作都在一个线程上完成的。
但在目前的单线程Reactor模式中,不仅I/O操作在该Reactor线程上,连非I/O的业务操作也在该线程上进行处理了,这可能会大大延迟I/O请求的响应。所以我们应该将非I/O的业务逻辑操作从Reactor线程上卸载,以此来加速Reactor线程对I/O请求的响应。
服务器多线程Reactor处理流程:
Reactor线程池中的每一Reactor线程都会有自己的多路复用器Selector、线程和分发的事件循环逻辑。
mainReactor可以只有一个,但subReactor一般会有多个。mainReactor线程主要负责接收客户端的连接请求,然后将接收到的SocketChannel传递给subReactor,由subReactor来完成和客户端的通信。
注册一个Acceptor事件处理器到mainReactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样mainReactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。启动mainReactor的事件循环。
客户端向服务器端发起一个连接请求,mainReactor监听到了该ACCEPT事件并将该ACCEPT事件派发给Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将这个SocketChannel传递给subReactor线程池。
subReactor线程池分配一个subReactor线程给这个SocketChannel,即,将SocketChannel关注的READ事件以及对应的READ事件处理器注册到subReactor线程中。当然你也注册WRITE事件以及WRITE事件处理器到subReactor线程中以完成I/O写操作。Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的循环逻辑。
当有I/O事件就绪时,相关的subReactor就将事件派发给响应的处理器处理。注意,这里subReactor线程只负责完成I/O的read()操作,在读取到数据后将非I/O事件——业务逻辑的处理放入到EventExecutorGroup工作线程池的EventExecutor中完成,若完成业务逻辑后需要返回数据给客户端,则相关的I/O的write操作还是会被提交回subReactor线程来完成。
扩展知识:Tomcat 同步/阻塞BIO的源码分析
基于阻塞I/O服务器流程:
服务器端的Server是一个线程,线程中执行一个死循环来阻塞的监听客户端的连接请求和通信。
当客户端向服务器端发送一个连接请求后,服务器端的Server会接受客户端的请求,ServerSocket.accept()从阻塞中返回,得到一个与客户端连接相对于的Socket。
构建一个handler,将Socket传入该handler。创建一个线程并启动该线程,在线程中执行handler,这样与客户端的所有的通信以及数据处理都在该线程中执行。当该客户端和服务器端完成通信关闭连接后,线程就会被销毁。
然后Server继续执行accept()操作等待新的连接请求。
优点:
- 使用简单,容易编程
- 在多核系统下,能够充分利用了多核CPU的资源。即,当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
缺点:该模式的本质问题在于严重依赖线程,但线程Java虚拟机非常宝贵的资源。随着客户端并发访问量的急剧增加,线程数量的不断膨胀将服务器端的性能将急剧下降。
- 线程生命周期的开销非常高。线程的创建与销毁并不是没有代价的。在Linux这样的操作系统中,线程本质上就是一个进程,创建和销毁都是重量级的系统函数。
- 资源消耗。内存:大量空闲的线程会占用许多内存,给垃圾回收器带来压力。;CPU:如果你已经拥有足够多的线程使所有CPU保持忙碌状态,那么再创建更过的线程反而会降低性能。
- 稳定性。在可创建线程的数量上存在一个限制。这个限制值将随着平台的不同而不同,并且受多个因素制约:a)JVM的启动参数、b)Threa的构造函数中请求的栈大小、c)底层操作系统对线程的限制 等。如果破坏了这些限制,那么很可能抛出OutOfMemoryError异常。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,不仅会带来许多无用的上下文切换,还可能导致执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统负载偏高、CPU sy(系统CPU)使用率特别高,导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
- 若是长连接的情况下并且客户端与服务器端交互并不频繁的,那么客户端和服务器端的连接会一直保留着,对应的线程也就一直存在在,但因为不频繁的通信,导致大量线程在大量时间内都处于空置状态。
适用场景:如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO服务器实现可能非常契合。
Java Questions and Answers
这里有东西被加密了,需要输入密码查看哦。
Microservices via Spring Cloud
目前各大科技公司都提供了各种云平台服务,对于普通地金融科技公司而言,从传统的内部维护基础架构的日子一去不复返。策略转向了开发面向多平台,多终端的服务开发,其中前端开发倾向于web,后端开发倾向于自包含而且能灵活大量部署的微服务架构。如何从传统的开发风格转变为适应云平台服务的应用开发成为了一个需要攻坚的课题。
采用微服务架构拥有诸多好处,在本文中将不做赘述,可参见微服务架构一文。目前,微服务架构已经从设计逐渐落地,开发者社区逐渐贡献出云生态的组件框架,能够让这一战略目标变为可执行方案。
Spring Cloud微服务框架
Spring家族拥有多个方向的项目,目前最为领先行业的就是Spring Framework, Spring Boot, Spring Cloud三大方向,分别致力于帮助开发者开发系统,简化应用初始搭建,以及实现微服务开发设计。
Spring Cloud提供了非常完整的一套微服务实施方案:
- 服务发现
- 分布式配置
- 客户端负载均衡
- 服务容错保护
- API网关
- 安全
- 事件驱动
- 分布式服务跟踪
当然,代码构建微服务只是微服务落地的第一步,为了支持灵活大量部署,微服务需要借助容器技术来快速部署到各个云平台服务提供商的虚拟机上,Docker则是容器技术实现的一个典范,我将在另一篇文章中介绍容器技术。
Spring Cloud常用组件
API网关
Spring Cloud Gateway和Netflix Zuul为所有微服务提供了一个单一入口点。API网关是一个单独的中间件。
Spring Cloud Gateway源码分析
处理流程:
- 基于webflux容器/Netty通信框架:NIO机制,事件循环监听端口请求
- 请求的Route Predicate函数式过滤匹配规则
- HTTP请求信息检查例如:Host,Query, Path, Header, Cookie
- 请求过滤器Filter处理和转发接收
- Pre型在请求转发前执行,可以做鉴权,限流等操作
- Post型过滤器可以对返回数据进行增强处理
- 下游服务可以为注册中心的地址/预先配置好的节点IP信息
安全——服务验证和授权
Spring Cloud Securty为微服务提供了一种灵活的用户验证机制,和授权模型。其中验证机制可以基于OAuth2.0标准下的OpenID协议完成,而用户服务授权模型则通过OAuth 2.0的token提供。云服务中的所有服务都应该引入服务验证和授权机制来保护内容服务的安全性。
如果需要更多的security功能,可以考虑引入spring security中的功能。本文将着重介绍基于OAuth2.0的微服务安全架构。
微服务中一般在gateway进行验证授权,而在下游微服务中只需要确认请求是经过认证的即可。关于鉴权的详细文章请见这里.
Spring Cloud Netflix
Netflix Eureka服务注册
Eureka是单独的服务组件,保证了A高可用,和P分区容忍性的中间件,与Zookeeper保证的C一致性,P分区容忍性不同,更加适合微服务架构,通过集群保证了高可用的动态服务注册以及心跳感知。Eureka一般和Ribbon放在同一个服务器上,所以在gateway上需要指向lb://abc-service就能保证负载均衡到对应的已注册资源服务中。
Netflix Ribbon负载均衡
Netflix Ribbon 采用拦截器将请求的Url进行负载均衡分发,从而达到内容微服务的负载均衡效果。Ribbon框架并不是单独执行,往往在前端服务中会通过(服务注册中心获取/API网关中写死)得到提供服务的IP地址,所以服务调用方引入Ribbon通过一定的均衡策略动态生成最终访问的IP地址。
全局使用既定的某种负载均衡策略:
1
2
3
4
public RandomRule randomRule() {
return new RandomRule();
}通过配置方式灵活配置服务提供者的负载均衡策略
1 | # 负载均衡策略 |
Ribbon负载均衡策略比较
| 策略名 | 策略声明 | 策略描述 | 实现说明 |
|---|---|---|---|
| BestAvailableRule | public class BestAvailableRule extends ClientConfigEnabledRoundRobinRule | 选择一个最小的并发请求的server | 逐个考察Server: 如果Server被tripped了,则忽略,再选择其中ActiveRequestsCount最小的server |
| AvailabilityFilteringRule | public class AvailabilityFilteringRule extends PredicateBasedRule | 过滤掉那些因为一直连接失败的被标记为circuit tripped的后端server,并过滤掉那些高并发的的后端server(active connections 超过配置的阈值) | 使用一个AvailabilityPredicate来包含过滤server的逻辑, 其实就就是检查status里记录的各个server的运行状态 |
| WeightedResponseTimeRule | public class WeightedResponseTimeRule extends RoundRobinRule | 根据相应时间分配一个weight,相应时间越长,weight越小,被选中的可能性越低。 | 一个后台线程定期的从status里面读取评价响应时间,为每个server计算一个weight;Weight的计算也比较简单responsetime 减去每个server自己平均的responsetime是server的权重;当刚开始运行,没有形成statas时,使用roudrobin策略选择server。 |
| RetryRule | public class RetryRule extends AbstractLoadBalancerRule | 对选定的负载均衡策略机上重试机制。 | 在一个配置时间段内当选择server不成功,则一直尝试使用subRule的方式选择一个可用的server |
| RoundRobinRule | public class RoundRobinRule extends AbstractLoadBalancerRule | roundRobin方式轮询选择server | 轮询index,选择index对应位置的server |
| RandomRule | public class RandomRule extends AbstractLoadBalancerRule | 随机选择一个server | 在index上随机,选择index对应位置的server |
| ZoneAvoidanceRule | public class ZoneAvoidanceRule extends PredicateBasedRule | 复合判断server所在区域的性能和server的可用性选择server | 使用ZoneAvoidancePredicate和AvailabilityPredicate来判断是否选择某个server,前一个判断判定一个zone的运行性能是否可用,剔除不可用的zone(的所有server),AvailabilityPredicate用于过滤掉连接数过多的Server。 |
Netflix Feign动态代理RPC调用
RPC远程调用的一种经典实现,为了让服务调用的代码跟普通方法调用一样方便,可以使用Netflix Feign动态代理被调用的服务接口,并且在底层实际使用HTTPClient进行调用。
Netflix Hystrix服务弹性保证
对于微服务的调用失败需要进行动态的感知,当大量请求失败后需要主动断路避免延迟。而且需要后备方式记录或者进行服务降级。在.NETcore 中对等的实现是steeltoe.
Hystrix熔断机制源码分析
基于注解@HystrixCommand和AOP实现,在方法执行前拦截的动态代理执行。对于有弹性机制需要的节点,需要引入Hystrix进行失败回退方法编写。
Hystrix手写代码示例
- 自定义注解 @WuzzHystrixCommand
1 |
|
- 编写切面类,实现简易的逻辑处理
1 |
|
- 编写测试,调用:
1 |
|
正常得调用是没有问题的,这个时候我们把服务提供方的服务接口里 sleep 3秒来模仿调用超时,在访问接口就会得到降级服务后的返回。
Spring Cloud Alibaba
Nacos 配置中心,负载均衡,服务注册
Nacos服务注册源码分析
- Nacos服务注册Naming Service源码分析
* 接受Nacos客户端的API调用注册生成Instance实例
* 将Instance放入serviceMap中ConcurrentHashMap集合中
* consitencyService.listen实现数据定期检查
* 通过Namespace对已注册服务的隔离
* 定时检查HeartBeat对已注册Instance实例进行检查,更新实例状态
* 对出现异常的服务进行基于UDP协议推送更新于PushService- Nacos服务方客户端注册源码分析
- Spring Boot自动启动NacosAutoServiceRegistration进行注册调用
- 监听ApplicationStartedEvent事件调用NacosServiceRegistry.register方法
- namingService.regiterInstance中创建BeanInfo,定时发送心跳包:executorService.schedule(task, period, unit)
- Nacos前端客户端服务消费者源码分析
- 客户端发起订阅请求会定期发起UpdateTask来获得最新地址
- 客户端也会提供本地EventListener回调实例处理出现异常的服务
- Nacos服务方客户端注册源码分析
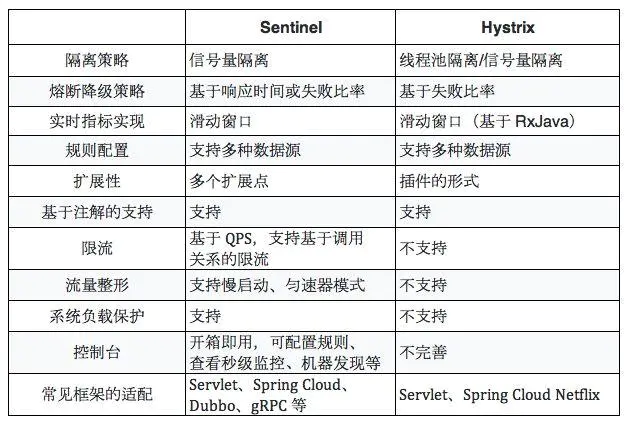
Sentinel 弹性限流/熔断模式
Sentinel和Hystrix对比
Seata 分布式事务
分布式事务解决了分布式系统中存储数据(数据库/缓存)一致性问题。
分布式事务解决理论
X/Open分布式事务模型
- AP: Application 应用程序
- RM: Resource Manager 资源管理者,数据库
- TM: Transaction Manager事务管理器/协调者
两段提交协议
- 准备阶段: TM同之RM准备事务,并告知准备结果
- 提交/回滚阶段:如果所有RM返回成功则执行提交完成指令,反之执行回滚指令。
存在问题:
- 同步阻塞数据库
- 容易失败,一个节点失败就回滚
- TM单点故障问题,造成RM锁死。
- 脑裂问题,二阶段部分提交问题。
三段提交协议
- CanCommit询问阶段: TM询问是否可以参与事务/超时。
- PreCommit准备阶段:如果所有RM确认可以,则发起事务,并返回结果/超时。
- DoCommit提交/回滚阶段:如果均成功提交则发起提交/回滚指令。
改进部分:
- 超时即失败机制,避免两阶段提交锁死等待问题。
- 提前确认节点状态
分布式事务解决方案
- 基于MQ的消息中间件实现TCC (Try-Confirm-Cancel)模型补偿型方案(幂等性实现,最大努力通知机制)
- 基于Seata模式的分布式事务框架(AT, TCC, Sega 和XA事务模式)
Seata源码分析
Spring Cloud Stream 发布/订阅流处理
Spring Cloud Stream支持消息中间件通信,因而可以支持多种高并发消息发布/消费场景:
Spring Cloud Stream包含如下四个核心部分:
- Spring Messaging
- Message, 消息对象,包含消息头和消息体
- MessageChannel, 消息通道接口,用于接收消息,提供send方法将消息发送至消息通道
- MessageHandler, 消息处理器接口,用于处理消息逻辑
- Spring Integration
- MessageDispatcher:消息分发接口,用于分发消息和添加删除消息处理器
- MessageRouter: 消息路由接口,定义默认的输出消息通道
- Filter:消息的过滤注解,用于配置消息过滤表达式
- Aggregator: 消息的聚合注解,用于将多个消息聚合成一条
- Splitter: 消息的分割,用于将一条消息拆分成多条
- Binders 目标绑定器,负责于外部消息中间件系统集成的组件
- doBindProducer: 为中间件绑定发送消息模块,让中间件能从MessageChannel接受到符合中间件格式的消息
- doBindConsumer:为中间件绑定接受消息模块,让中间件能够发送符合Spring Message标准的消息到MessageChannel
- Bindings 绑定生成的桥梁,支持Kafka,RabbitMQ中间件
RocketMQ 分布式消息通信源码分析
消息发送流程源码分析:
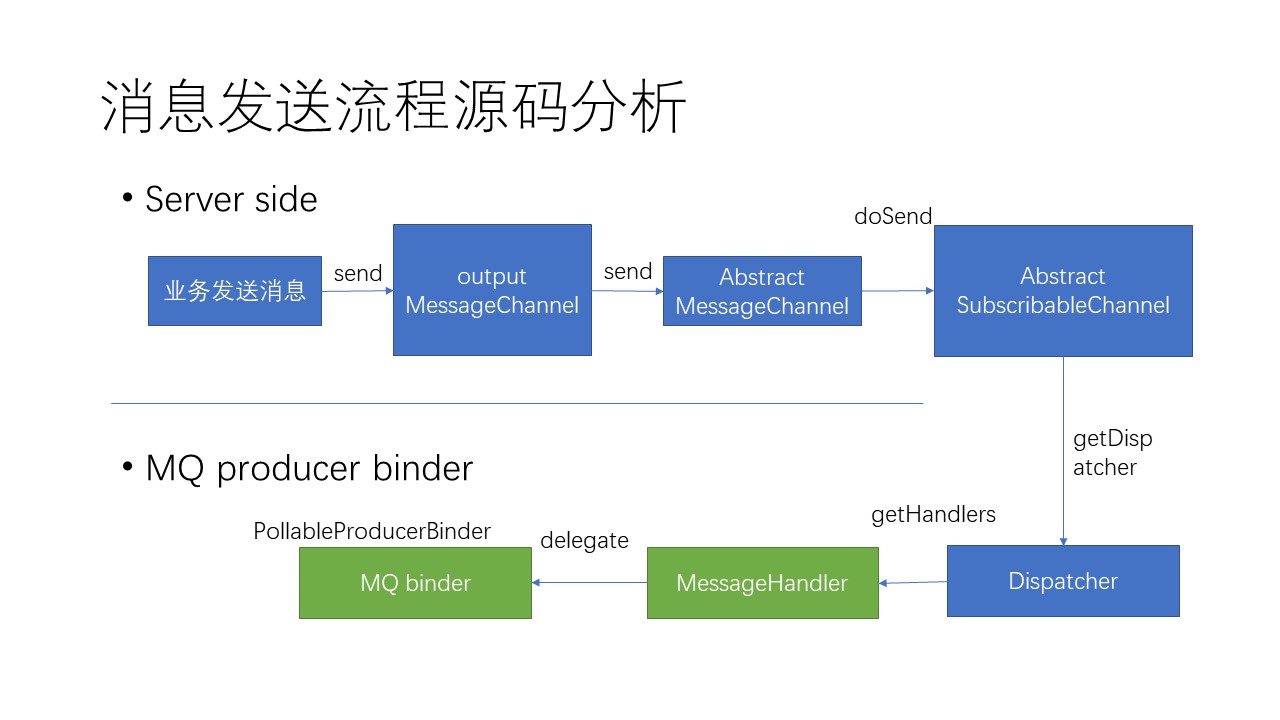
除了负责和Spring Cloud服务器中的Messaging集成之外,RocketMQ Binder还负责和MQ中间件集群通信,源码分发布/订阅两部分,分别如下:
- 使用RocketMQTemplate真正发送MQ消息到中间件
- 同时创建ConsumerEndpoint和input MessageChannel监听MQ订阅消息,并且负责转发给下游
- 消息的消费分为顺序消费和并发消费,分别由DefaultMessageListenerOrderly,DefaultMessageListenerConcurrently实现,通过binders的配置设定。
消息订阅流程源码分析:
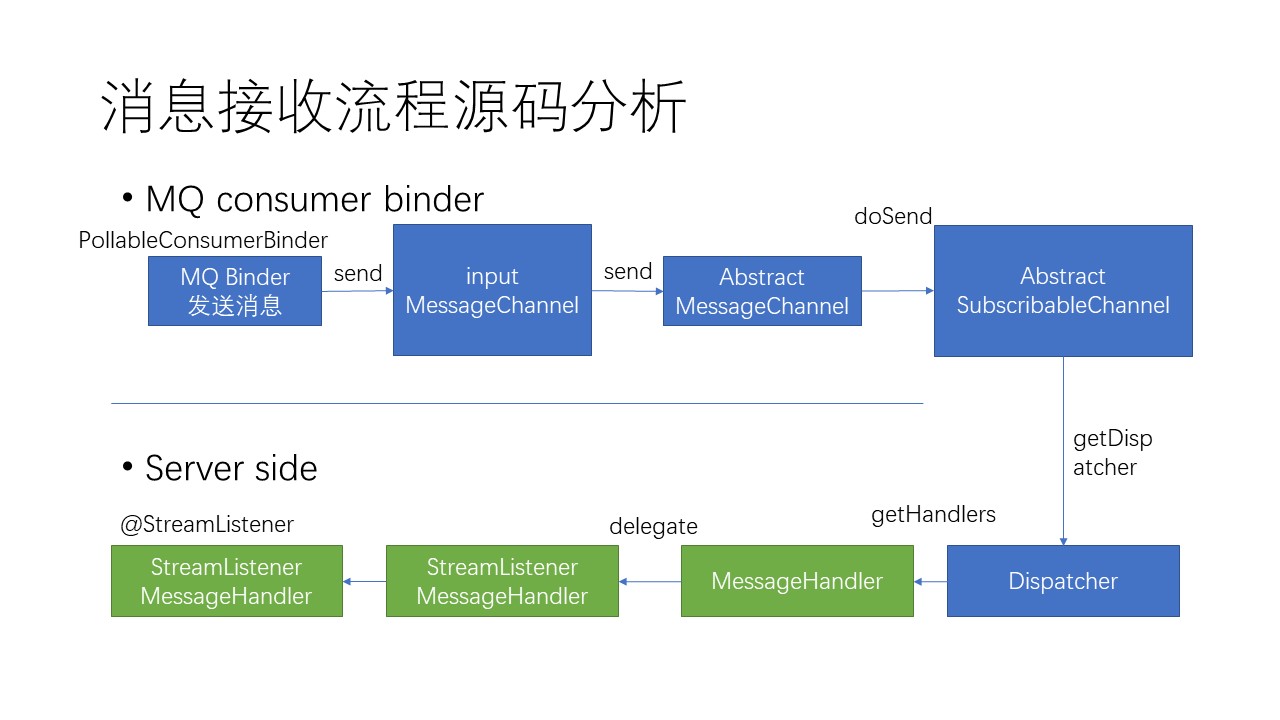
其中,服务器对消息的接收,是基于注解方式注入到响应的业务方法中的。这就是在业务代码中,不需要为接收信息创建MessageChannel,却能拿到信息体中的反序列化后信息。
RocketMQ 消息使用场景与实现
RocketMQ 顺序消息实现
顺序发送消费场景:订单创建、支付、退款流程处理,数据库BinLog信息消费等等。
- 顺序发送需要将消息发送到同一队列即可,通过基于消息ID的哈希分队选择器即可完成。
- 顺序消费需要binders中配置好ConsumerMQ的集群消费模式,即每条消息只会被ConsumerGroup中的一个Consumer消费。通过Consumer拿Broker独占锁实现。消费成功后会提交并更新消费进程,避免重复消费。代码如下:
1 | try{ |
RocketMQ 普通消息发送实现
普通消息在队列选择可以由两种机制:
- 轮询机制:轮流使用每个队列发送消息
- 故障规避机制:
RocketMQ 消息并发消费实现
并发消费场景下,消息队列允许Consumer的线程消费池可以向同一个队列消费信息,并且每个消费线程消费信息会有自己的进度信息。
RocketMQ 分布式事务消息实现
为分布式事务处理提供了通信基础。
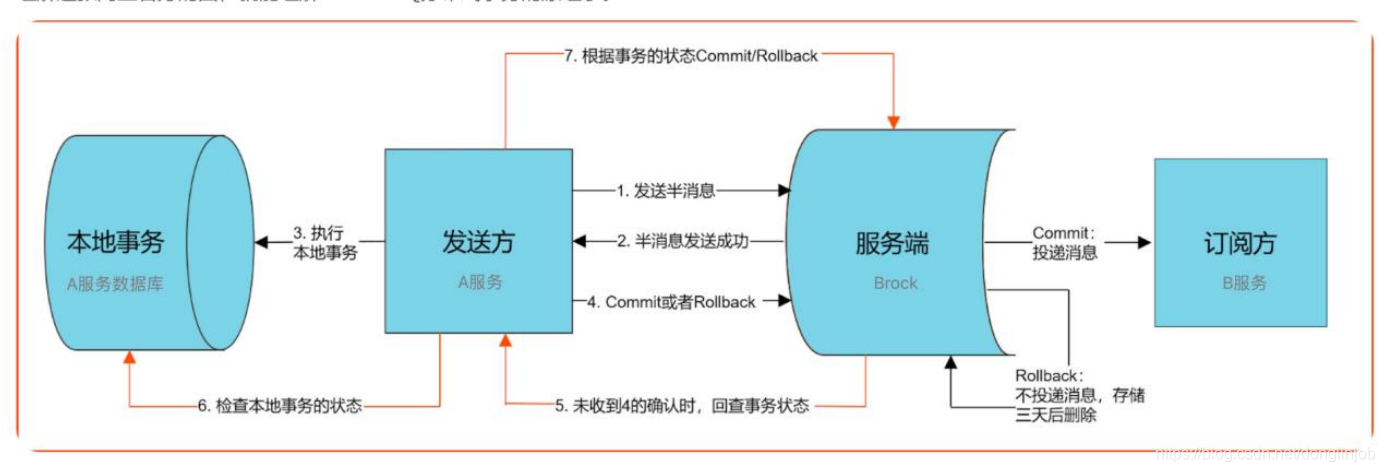
Rocket发送事务消息:
Rocket发送事务消息是二次提交的,第一次发送prepare提交到服务器时消息主题会替换为RMQ_SYS_TRANS_HALF_TOPIC。等到本地事务执行完毕以后才进行二次提交,这时会发送给原本消息的topic。
由producer发送prepare(半消息)给MQ的broker。MQ会把消息记录到本地,然后回复prepare消息状态给producer。
prepare消息发送以后获取发送状态,如果是成功则执行本地业务(本地事务),根据本地事务执行结果手动返回相应状态(RocketMQLocalTransactionState.COMMIT、RocketMQLocalTransactionState.ROLLBACK等)给MQ。
如果是COMMIT则说明本地事务执行成功,prepare为可提交状态,MQ收到COMMIT消息就会发送给consumer,然后consumer执行本地业务。如果是ROLLBACK则会删除prepare消息。
如果MQ一直没收到返回状态则会启动定时任务检查本地事务状态
消费者、生产者的事务各由开发者自己保证。MQ的事务是由MQ保证,这里会根据使用者配置的参数来决定如何执行。
RocketMQ消费模式
- at-most-once最多一次
- at-least-once最少一次,RocketMQ通过消费者ACK机制支持至少一次
- exactly-only-once仅此一次
RocketMQ实现原理
高性能设计
高可用设计
Office 365 Addin ESC POC
project bootstrap
Demo项目是通过VS2019自带的Addin模板生成。默认debug模式部署在一个o365 dev tenant上。目前已有Github demo项目也可以直接下载,相关链接。
Demo 项目原型简述
引入demo项目是一个查看邮件各种属性的ESCPOC项目,在读取一封邮件时,可以点击ESCPOC按钮查看邮件的属性。在启动debug并上传manifest后,点击Ribbon上的MyAddinGroup按钮,显示如下图所示:

我们的目标POC项目是一个非常简单的发送弹框程序,需要订阅每一封邮件的发送事件itemsend并且根据Web API调用结果显示一个web UI.
ESCPOC.xml 修改剖析
Manifest文件是O365插件加载的关键配置,需要完全符合schema定义的规则才能正确显式UI以及相应的回调API。
- Validation
Manifest 文件具有很强的格式要求,需要运用微软提供的工具对自己的manifest文件进行语法检查。
1 | #install latest version |
- 创建ItemSend相关配置
目前微软已经有开源的示例代码于https://github.com/OfficeDev/outlook-add-in-command-demo,可以作为参考。1
<Event Type="ItemSend" FunctionExecution="synchronous" FunctionName="itemSendHandler" />
注意配置上下文需要在VersionOverrides 1.1框架下。
O365 环境准备
对于跨平台的O365 Addin,一个合法的O365账号是需要的,而且需要拥有上传插件的权限。在用用MSDN订阅的情况下,可以创建合适的E3等级Office Tenant。例如本文则使用huangsun@sunnyhll.onmicrosoft.com作为测试账号,密码为系统密码。
Web Addin查看可以点击Outlook桌面客户端的Manage Addin按钮,也可以在https://outlook.office365.com/owa/?path=/options/manageapps 链接中看到。可以看到即使安装了很多插件,这些插件却不是实时安装在本地Outlook桌面客户端上的, 而是在需要访问的时候才进行加载执行的。
开启ItemSend事件监听
相关链接.
“My Custom Roles”权限
对于个人O365账号,这里不需要进行权限获取,Microsoft Tenant默认每个客户的SideLoad权限开启。
Web Addin部署
对于Outlook Web Addin, 主要分成两部分部署:
- Manifest配置文件部署,在Exchange Mailbox 上注册插件
- 插件服务部署,必须采用https协议,插件服务前后端本身需要在同一域名下。
部署完成即可进行测试。
Excel Addin原型
Excel Addin属于Office Addin一部分,example link: https://github.com/OfficeDev/Office-Add-in-samples/
Effective Java
本文是Effetive Java一书提出地90条Java代码规范建议,具体内容需要查看相应地书籍内容,本文仅作为索引复习回忆。
创建与销毁对象
用静态工厂方法代替构造器
遇到多个构造器参数时要考虑使用构建器(builder)
用私有构造器或者枚举类型强化Singleton属性
通过私有构造器强化不可实例化的能力
优先考虑依赖注入来引用资源
避免创建不必要的对象
消除过期的对象引用
避免使用中介方法和清除方法
try-with-resources优先于try-finally
对于所有对象都通用的方法
覆盖Equals时请遵守通用约定
覆盖equals时总要覆盖hashCode
始终要覆盖toString
谨慎的覆盖clone
考虑实现Comparable接口
类和接口
使用类和成员的可访问性最小化
要在公有类而非公有域中使用访问方法
使可变性最小化
复合优先于集成
要么设计继承并提供文档说明,要么继承
接口优于抽象类
为后代设计接口
接口只用于定义类型
类层次优于标签类
静态成员类由于非静态成员类
限制源文件为单个顶级类
泛型
请不要使用原生态类型
消除非受检的警告
列表由于数组
优先考虑泛型
优先考虑泛型方法
利用有限限制通配符来提升API的灵活性
谨慎并用泛型和可变参数
优先考虑类型安全的异构容器
枚举和注解
用enum代替int常量
用实例域代替序数
用EnumSet代替位域
用EnumMap代替序数索引
用接口模拟可扩展的枚举
注解优先于明明模式
坚持使用Override注解
用标记接口定义类型
Lamda和stream
Lamda优先于匿名类
方法引用优先于Lamda
坚持使用标准的函数接口
谨慎使用Stream
优先选择Stream中无副作用的函数
Stream要优先用Collection作为返回类型
谨慎使用Stream并行
方法
检查参数的有效性
必要时进行保护性拷贝
谨慎设计方法签名
慎用重载
慎用可变参数
返回零长度的数组或者集合,而不是null
谨慎返回optional
为所有导出的API元素编写文档注释
通用编程
将局部变量的作用域最小化
for-each循环优先传统的for循环
了解和使用类库
如果需要精确的答案,请避免使用float和double
基本类型优先于装箱基本类型
如果其他类型更适合,则尽量避免使用字符串
了解字符串连接的性能
通过接口引用对象
接口优先于反射机制
谨慎地使用本地方法
谨慎地进行优化
遵守普遍接受的命名惯例
异常
只针对异常的情况才使用异常
对可恢复的情况使用受检异常,对编程错误使用运行时异常
避免不必要地使用受检异常
优先使用标准的异常
抛出与抽象对应的异常
每个方法抛出的所有异常都要建立文档
在细节消息中包含失败捕获信息
努力使失败保持原子性
不要忽略异常
并发
同步访问共享的可变数据
避免过度同步
executor,task和stream优先于线程
并发工具优先于wait和notify
线程安全性的文档化
慎用延迟初始化
不要依赖于线程调度器
序列化
其他方法优先于Java序列化
谨慎地实现Serializable接口
考虑使用自定义地序列化形式
保护性地编写readOjbect方法
对于实例控制,枚举类型优先于readResolve
考虑用序列化代理代替序列化实例
Microservice Architecture
Why Microservice
- Heterogenious technical stack:
支持多重技术栈,由于HTTP协议被多种编程语言支持,微服务可以用多种语言实现。 - Robustness:整个App mesh网络不会因为单一的微服务的奔溃而停止工作。
- Extensions:可以针对单一微服务进行扩展。
- Simple deployment:微服务可以进行独立部署,不需要因为单一服务升级而多次部署。
- Efficiency:微服务小团队开发高效敏捷。
- More client support:多种前端客户端支持,可以重复利用同一个微服务后端网络。
- Migration:基于单一微服务迁移的整体升级,阻碍更小。
What is Microservice
微服务就是一些协同工作的小而自治的服务。
How to architect Microservices
微服务特点
Loose coupling松耦合
High Cohesion高内聚
上下文边界确定
业务或者职能的界限,往往也可以作为微服务架构中的服务边界。不同的业务只能之间的内部细节并不需要相互知晓。同一个事件,在不同的业务职能会有不同的体现,但是在内部细节上却没有相互交叉。
共享和隐藏模型设计
限界上下文的确立,能够帮助确立共享模块,对于处于两个上下文边界上需要共同的消息,可以确立一个共享模块,专门进行信息共享。同时,对于上下文内部的逻辑,也能进行对应的逻辑模块设计,从而完成对于整个上下文的设计。
切勿过早划分
对于一些过早划分的业务产品,警惕由于后期需求用例改变造成多个上下文之间的重叠。比较推荐的是先进行单体设计,不进行划分,在服务稳定之后再进行划分设计迁移,基于以有代码进行划分,比从头开始构建微服务简单得多。
逐步划分上下文
不断对上下文的界限进行迭代,从复杂的共享模型中慢慢抽出简单的共享模型,将嵌套的模块逐步上升到顶层模型,对其中某些紧密关联模型进行共享。当然,模型共享的粒度取决于代码是分开维护还是集中维护,如果是集中维护也未尝不可进行嵌套模型共享。
微服务的集成
微服务之间的通信机制,可以成为微服务的集成。微服务间的API相互调用设计需要注意一下几个方面:
为用户创建接口
用户上下文会触发一定特定的流程。
共享数据库
数据库是多个微服务共享的,因为每个微服务都可能对同一个数据库进行修改。
同步与异步通信模式
两种不同的通信模式中,同步模式会阻塞线程,而异步模式是基于事件响应请求的,能提降低耦合性,提高吞吐量。
编排与协同
编排和协同是两种管理流程的架构风格。(同步)编排是通过一个中心执行者将每一步的步骤执行,知道获取最终的结果。(异步)协同则是以事件为机制进行执行,执行单元会订阅事件,API调用会触发一个事件,事件订阅者则会自动执行响应的流程。后者会需要监控服务,监控结果要映射到流程中,troubleshooting难度增加,这是一个难题。ATOM是一个符合REST规范的协议可以通过它提供资源feed的发布服务,客户端可以消费该信息。
RPC与REST
远程调用允许进行本地调用,事实上是由某个远程服务器产生。RPC会有一定的技术耦合要求。protocol buffers, Thrift是比较推荐的RPC框架。REST则是RPC的一个替代方案。通过URI对客户端与服务器进行了松耦合。
Json与XML
JSON与XML都是一种有效的数据序列化格式,前者更加流行XML对超媒体控制更加好。
API重定向
API的重定向常常发生在多个API版本共存的时候,当老版本的API准备deco时,需要绞杀者模式将旧的API拦截,选择是否替换成新版本的实现。当旧版本的访问完全消失时,再删除旧的API。
拆分成微服务
- 寻找独立的上下文边界——接缝
- 拆分数据库表格的混合加载功能,放弃直接利用数据库命令访问上下文边界间的外键,改为由代码(微服务服务API)
- 共享的静态数据改由配置维护关联。
- 针对共享数据,建立合适的领域进行关联,例如代码中建立客户关系,来维护财务——客户——仓库关系。
- 共享表格,对于有大量列信息的表格,可以根据上下文边界将表格拆分成两个。
- 自数据库开始进行代码重构。
- 事务的边界重构,对于多表的修改操作,需要协同处理错误,或者利用分布式事务处理工具代为管理事务。
- 拆分后的数据库在制作报表时会出现问题,因为不再能用sql语言进行表格操作。解决方法可以是主动定期导出表格合并,或者基于修改时间订阅导出行为。
部署微服务
- 准备CI系统,流水线,自动化流程
- Paas,Docker打包部署
测试
- 单元测试
- 服务测试(mock/打桩)
- E2E测试 —— 消费者驱动的测试
- 上线 —— 金丝雀发布法
监控
微服务的监控难度高于单一服务器应用。微服务包含多个服务,而每个服务的实例个数不等。关联标识可以帮忙关联同一个事件服务调用的日志,采用统一标准化的格式能够更快的辅助错误定位。
监控的内容包括CPU,响应时间,以及合理的语义监控(合成事务监控)。
微服务安全
- 身份验证和授权
身份雅正确认了登录者的身份。授权机制能够确定登录者可以访问和进行的操作。常见的单点登录(Single Sign-On),企业级标准为SAML和OpenID Connect,前者基于SOAP标准,后者基于OAuth2.0. 身份提供者可以是外部系统或者内部目录服务,如LDAP/AD等。
微服务的身份认证和授权部分可以依托于网关,网关可以作为认证代理,通过网管认证的所有查询和操作都可以发送到微服务集群任意一个实例中处理。微服务内部可以决定身份可以授权的操作。
- 服务间的身份验证和授权
服务之间的身份验证是指微服务的各个服务之间的身份验证和授权,一般来说有如下几种方式管理:
- 在微服务边界内允许一切
- HTTP(S)基本身份验证(HTTP明文传输认证信息,如果基于SSL认证则需要管理多台服务器之间的自签发证书。)
- 使用SAML或OpenID Connect认证授权,可以有效的避免中间人攻击,这样每个服务也需要一个身份。
- 客户端证书(采用客户端X.509证书,通过TLS层协议对服务器验证进行保证。)
- HMAC(Hash-based Message Authentication Code,请求主题和私有密钥一起被哈希处理后进行发送,服务器使用请求主题和自己私钥副本重建哈希值。如果匹配则接收,防止的中间人攻击。)
- JWT(JSON Web Token,JWT的原则是在服务器身份验证之后,将生成一个JSON对象并将其发送回用户。当用户与服务器通信时,客户在请求中发回JSON对象。服务器仅依赖于这个JSON对象来标识用户。为了防止用户篡改数据,服务器将在生成对象时添加签名。)
- API密钥(API密钥是给予某种形式的秘密令牌的名称,该秘密令牌与Web服务(或类似)请求一起提交以便识别请求的来源。密钥可以包括在请求内容的一些摘要中,以进一步验证原点并防止篡改值。)
- 数据加密(现存多种算法进行数据加密,密钥可以通过加盐哈希保护)
- 深度防御
- 防火墙
- 日志
- 入侵监测
- 网络隔离
- 操作系统安全
- OWASP标准(Open Web Application Security Project开放式Web应用程序安全项目,https://www.owasp.org)
系统设计与组织架构
公司团队的组织架构会影响系统设计。
单地域的团队拥有更加好的灵活性和效率,因此对于异地团队最好的办法是想办法合理拆分,让不同的团队负责不同的松耦合模块。
每个团队需要负责对服务的需求,更改,构建,部署到运维,自治的团队能够很好的激励团队的效率。
小团队规模,少于10个人的团队能够对其所负责的系统整个生命周期负责,技术选择和实现上具有灵活性。当然这个对服务的高效构建部署效率很高,比如利用云服务的Infra来轻松构建CI/CD流程。
规模化微服务
允许故障无处不在,故障永远会在意想不到的时候发生,所以微服务本身需要能够允许故障出现,硬件上也不用为避免故障作特殊设计。
服务平行扩容阈值控制,需要参考一些系统参数,响应时间/延迟,可用性,数据持久性(丢包率)。
当故障出现时,适当的服务功能降级,允许应用能够在其他方面能够正确运行而不是直接返回错误界面。
微服务延迟的影响控制,通常会导致worker线程池的阻塞队列超长,最终线程池没有可用的线程而宕机。合理设置线程池的舱壁bulkhead,在舱位线程用尽后断路该服务,避免因为单个服务的延迟影响导致所有的线程都阻塞于同一个服务。
数据库扩展,当数据库需要服务于高吞吐量服务时,可以通过数据库副本,RDBMS系统,扩展写操作,独立CQRS读写分离系统,等多种方式扩展。
缓存可以优化重复请求,氛围哭护短、代理和服务器端缓存。
自动伸缩,当云管理能够强大到自动调整微服务实例个数,就可以基于当前流量进行自动调整。
CAP定理(一致性consistency、可用性availability和分区容忍性partition tolerance)是分布式系统中需要控制好的三个平衡。
服务发现,可以通过DNS服务器进行关联,负载均衡服务器将查询分发到不同的IP服务器上。
动态服务注册,新加入的微服务实例的IP应用信息需要能共享给其他服务,Zookeeper,consul和Eureka等服务可以管理配置管理和服务发现。
文档服务,为API构建合适的文档,Swagger可以很好的自动生成API文档,HAL和HAL浏览器也可以客户端逐步探索API。
自描述系统(UDDI Universal Description Discovery and Integration通用描述发现与集成服务),这个标准能帮助了解哪些服务正在运行。