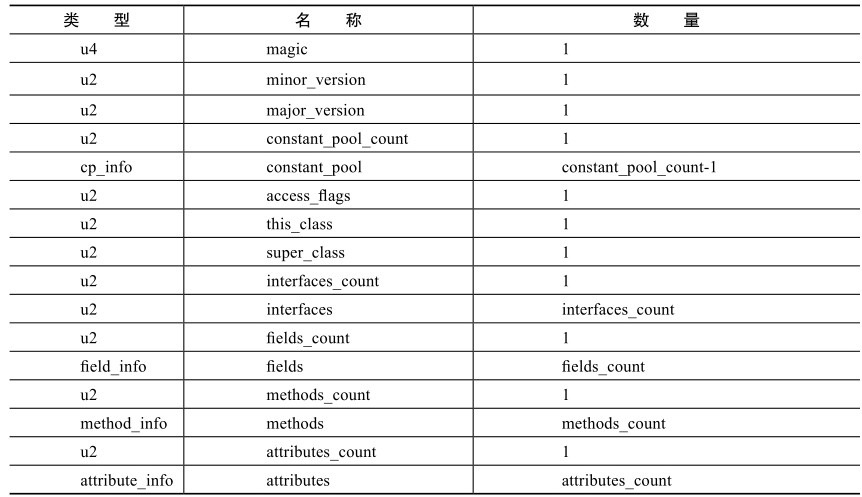
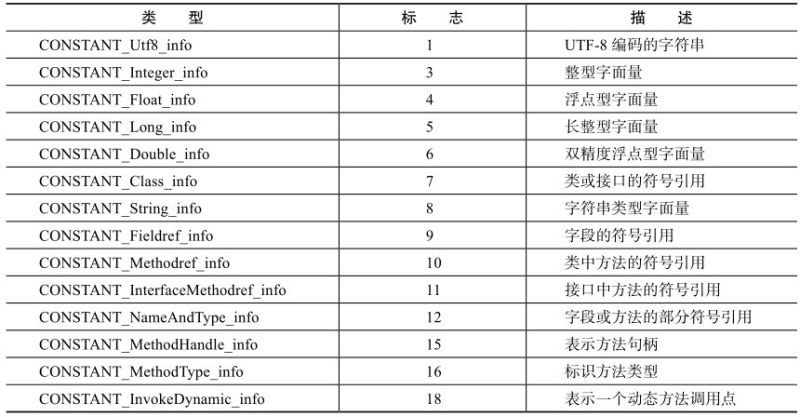
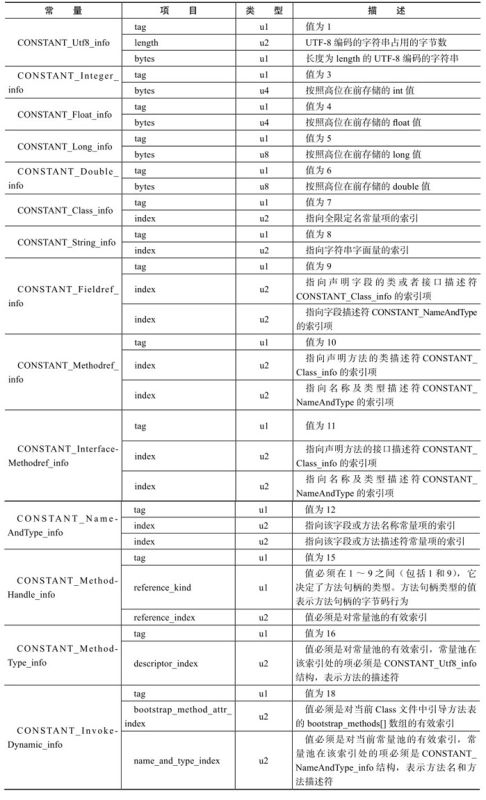
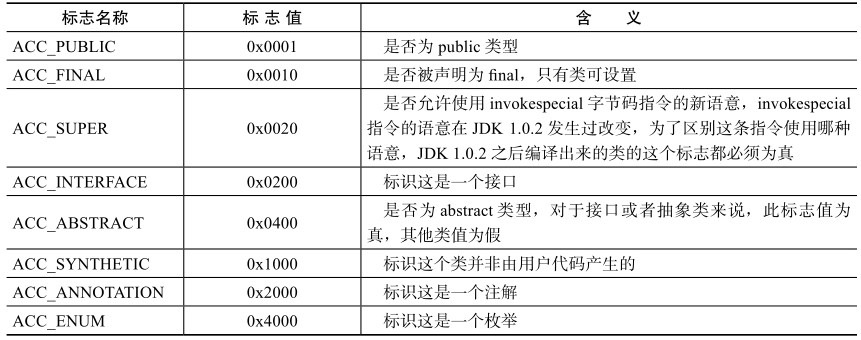
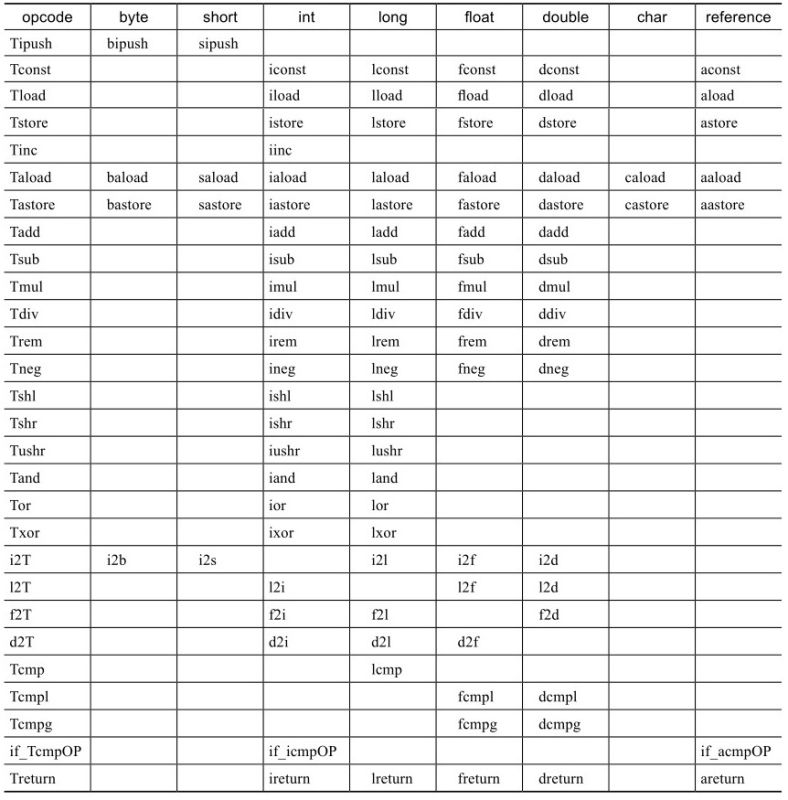
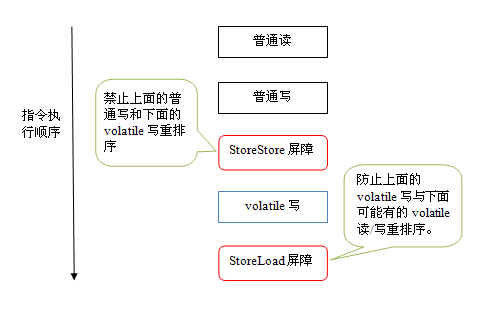
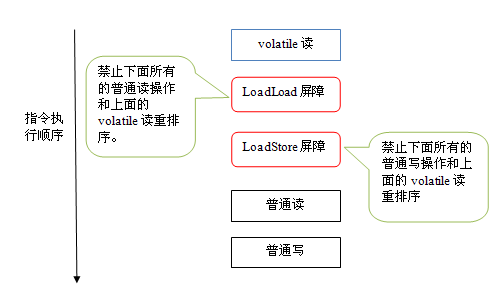
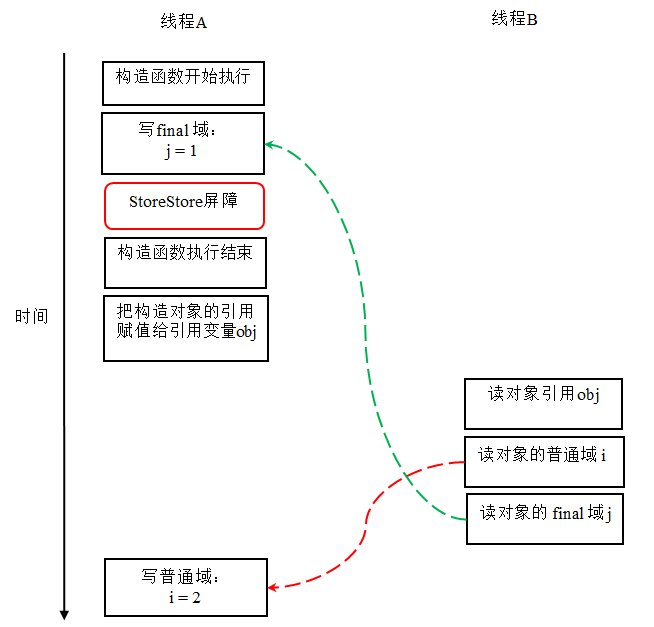
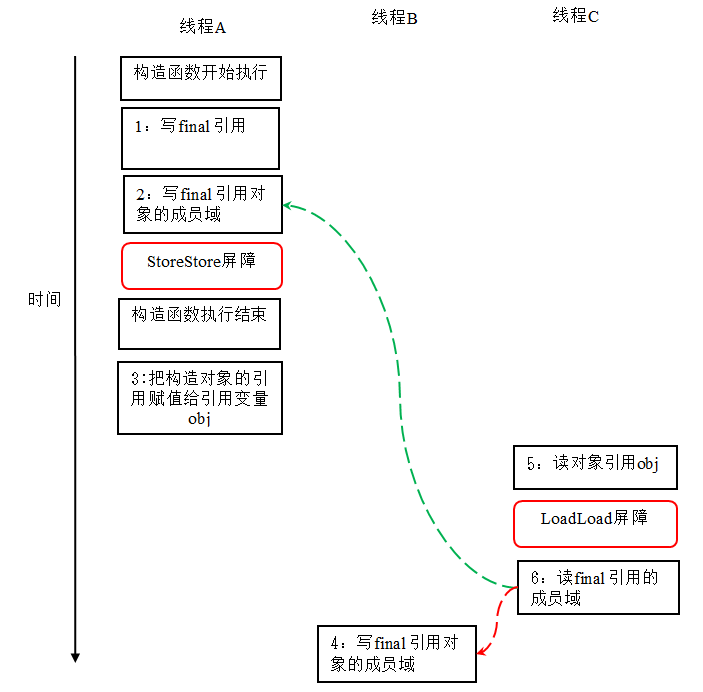
本文将从计算机底层实现的角度描述Java目前的并发工具的实现细节。
Synchronized实现细节 JVM基于进入和退出Monitor对象来实现方法同步和代码块同步。即使用monitorenter和monitorexit指令实现的。
monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处。
线程执行到monitorenter指令时会尝试获取对象所对应的monitor的所有权/对象锁。
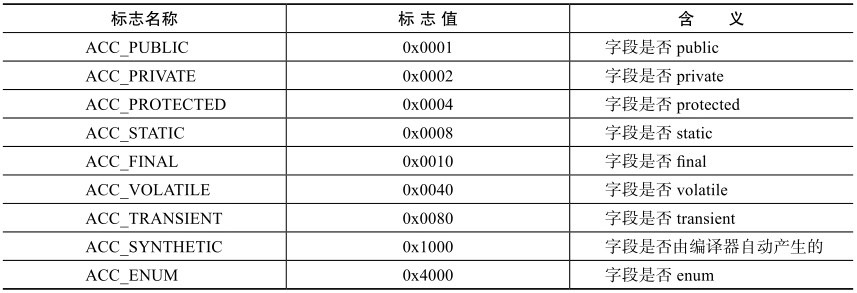
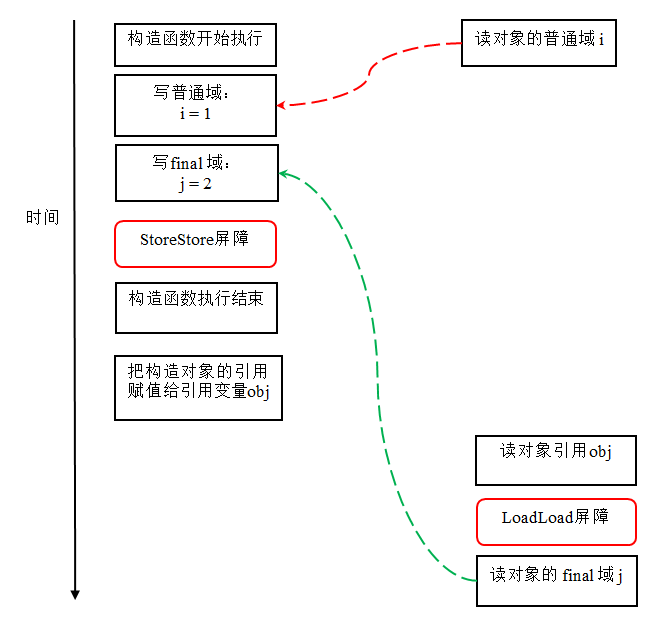
Synchronized用的锁是存在与Java对象头里。Java对象头的结构于这里 。
锁一共有4种状态,级别从低到高分别是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。
偏向锁:
1. 设置:当一个线程获取锁,对象锁从无锁状态变成偏向锁,允许该线程反复拿锁。(已经有identity hashcode的对象不会使用偏向锁)
2. 撤销:当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,撤销后变成无锁状态,膨胀成轻量级锁。(偏向对象如果需要identity hashcode则会膨胀成重量级锁)
** identity hash code: 未被覆写的 java.lang.Object.hashCode() 或者 java.lang.System.identityHashCode(Object) 所返回的值。
轻量级锁:
1. 设置:JVM在当前线程栈帧中创建用于存储锁纪录的空间,并将对象头的MarkWord复制到锁纪录中。然后尝试用CAS操作将指向锁纪录指针放入MarkWord空间。如果成功,则获得锁,如果失败,则自旋来获取锁。
2. 解锁: CAS操作将Displaced MarkWord
放回到对象头,如果成功,表示没有竞争。如果失败说明存在竞争,即两个线程中解锁线程无法将MarkWord取回,因为另一个自旋线程已经尝试将MarkWord放到自己线程的锁记录中,CAS会发现MW的owner不是自己,膨胀成重量级锁。阻塞所有没拿到锁的线程。
重量级锁:
1. 设置:重量级锁会阻塞拿不到锁的所有线程,减少了自旋带来的CPU开销。一旦升级成重量级锁,将不会降级锁。
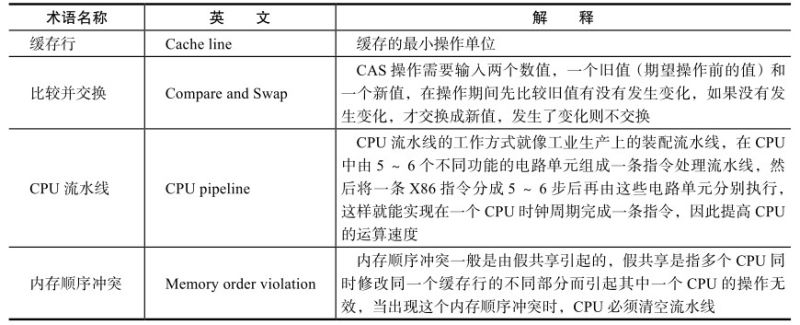
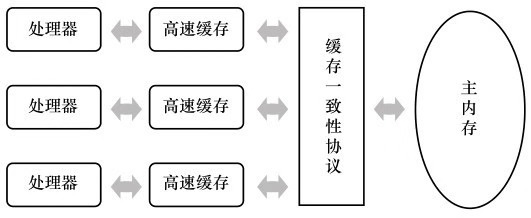
原子操作的实现原理 原子操作主要依赖的是计算机的如下几个CPU基本操作:
为了达到原子操作的目的,CPU会通过如下两种方式确保在某一时刻,只有一个CPU对共享内存中的数据进行写操作:
通过总线锁保证原子性:CPU会提供一个LOCK #信号,将其他处理器的内存访问请求阻塞住,从而独占共享内存。
通过缓存所定保证原子性:需要处理器支持,开销较小,CPU修改缓存行进行缓存锁定,那么另一个CPU就不能同时缓存该内存数据,这是通过处理器的缓存以执行机制来保证的。
JVM中是可以通过锁和循环CAS操作来保证该变量的赋值成功的。
其中循环CAS操作可能带来如下问题:
ABA问题,值已经变化,但CAS的旧值比较返回true,解决方法是加入变量版本号。
循环时间开销大,可以通过JVM支持CPU的pause指令提升效率。
只能保证单一共享变量的原子性,可以通过AtomicReference方式合并变量成为一个新的对象处理。
锁机制,除了偏向锁,锁本身就是通过循环CAS实现拿/释放锁。
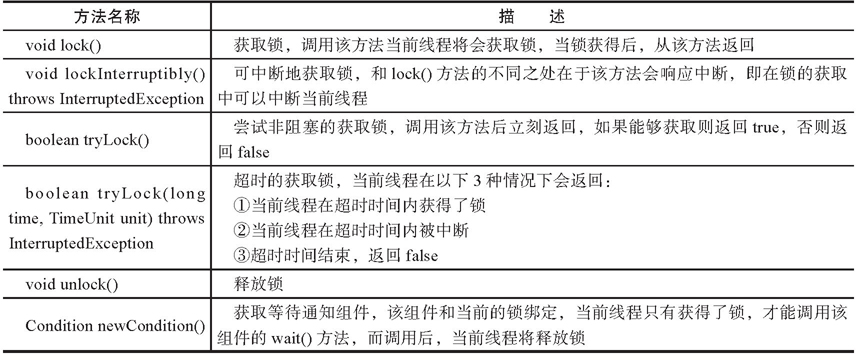
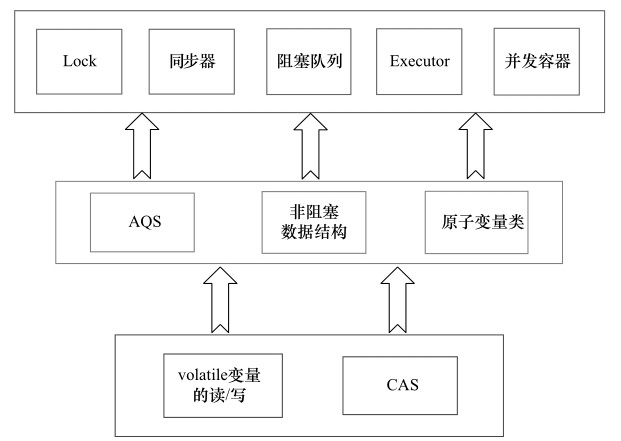
Lock锁实现细节 对比与synchronized中采用的锁, Lock有如下不同之处:
以下是Lock的API介绍,本文将展示API的实现细节:
ReentrantLock的实现依赖于Java同步器框架,下面将着重讲解同步器框架的实现。对于公平锁和非公平锁的实现,AQS基本实现都一样,除了在公平锁释放节点是会调用hasQueuedPredecessors()方法判定是否队列中用等待节点,从而保证不会有线程在释放阶段竞争到锁,让线程串行化拿锁。
队列同步器AQS框架实现细节
http://www.cnblogs.com/waterystone/p/4920797.html
类如其名,抽象的队列式的同步器,AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch。
实现细节在另一篇文章 已讲述。
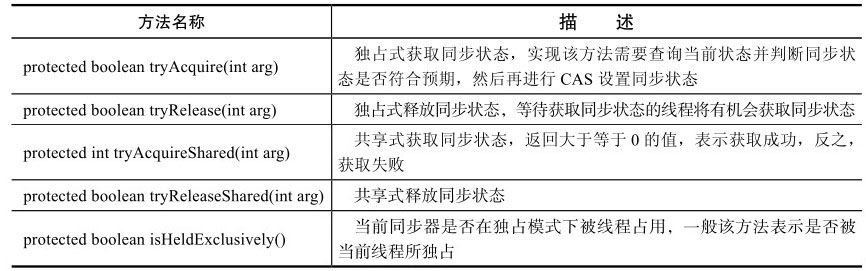
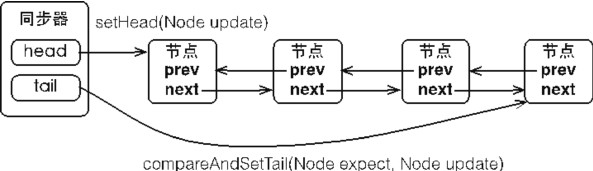
同步器本身是一个抽象类,实现了同步器的类可以完成线程同步,包括:同步队列,独占式同步状态获取与释放,共享式同步状态获取与释放及超时获取同步状态。队列同步器使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。
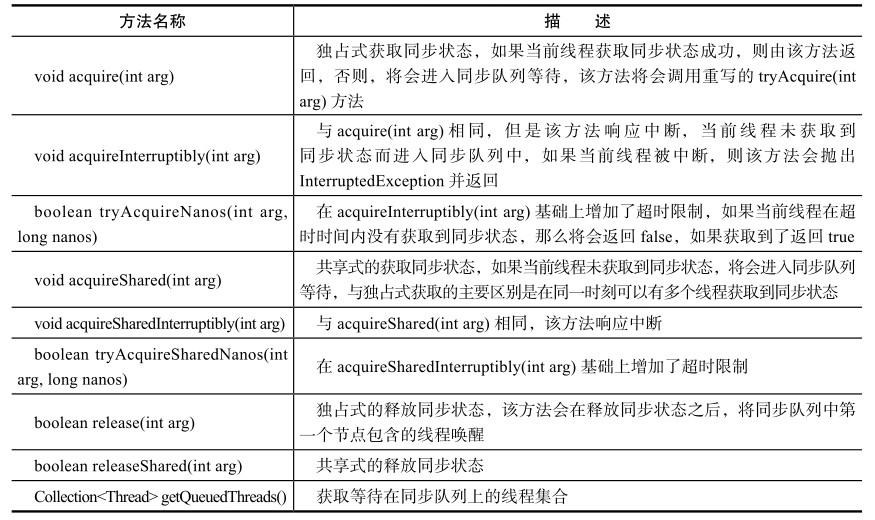
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 abstract class AbstractQueueSynchronizer { private volatile int state; protected final in getState () ; protected final void setState (int newState) ; protected final boolean compareAndSetState (int expect, int update) ; protected boolean tryAcquire (int arg) ; protected boolean tryRelease (int arg) ; protected int tryAcquireShared (int arg) ; protected boolean tryReleaseShared (int arg) ; protected boolean isHeldExclusive () ; public final void acquire (int arg) ; public void acquireInterruptibly (int arg) ; public boolean tryAcquireNanos (int arg, long nanos) ; public void acquireShared (int arg) ; public void acquireSharedInterruptibly (int arg) ; public boolean tryAcquireSharedNanos (int arg, long nanos) ; public boolean release (int arg) ; public boolean releaseShared (int arg) ; public Collection<Thread> getQueuedThreads () ; }
支持重写方法的不同重写可以实现不同的锁,具体如下:
在实现重写方法可以调用模板方法,具体如下:
下文将分类别讲述模板方法的实现:
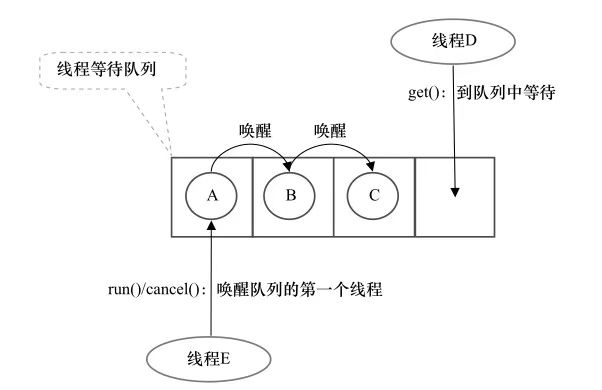
同步队列 同步器内部有一个同步队列(FIFO双向队列)进行同步状态管理。当前线程获取同步状态失败时,同步器会将当前线程及等待状态等信息构造成为一个节点并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,会把节点中的线程唤醒,使其再次尝试获取同步状态。
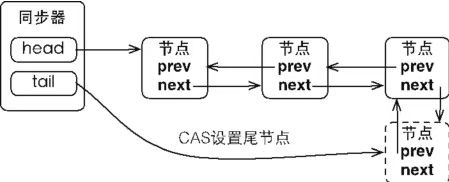
compareAndSetTail(…)方法基于CAS设置尾节点,保证队列更新的线程安全。
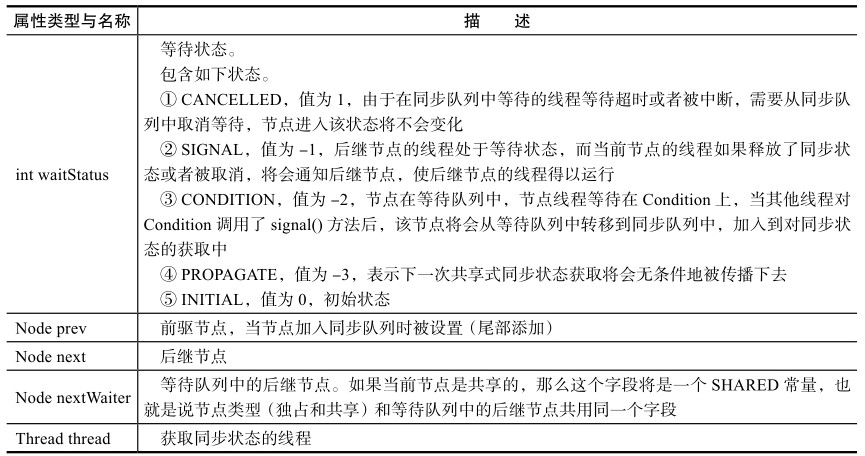
1 2 3 4 5 6 7 public class Node { private int waitStatus; private Node prev; private Node next; private Node nextWaiter; private Thread thread; }
具体描述如下图所示:
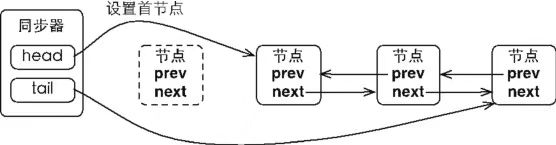
当首节点的线程成功地获取了同步状态/锁,该线程会将首节点设置为后继节点,并且将本节点的next引用断开即可。然后线程执行任务,任务完成后唤醒后继节点。具体的节点处理实现由锁的类型(独占/共享)的模板方法Release/ReleaseShared实现。
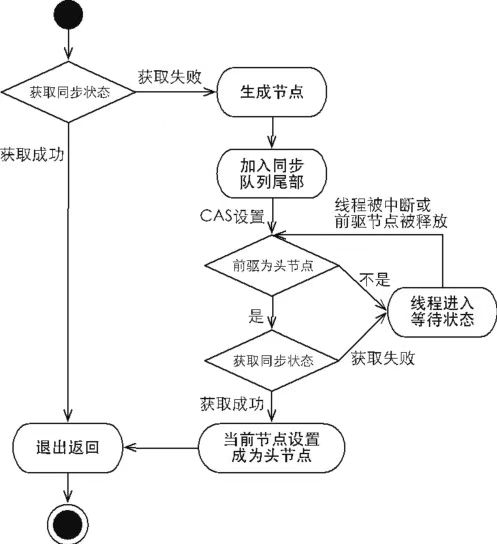
当一个线程无法获取到同步状态,会被构造成节点加入到同步队列尾部,CAS设置能保证节点加入过程的线程安全。过程图如图所示。
节点操作由具体的模板方法AcquireQueued/AcquireShared等实现,而节点封装和入队细节如下列代码所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public abstract class AbstractQueuedSynchronizer { private Node head; private Node tail; private Node addWaiter (Node mode) { Node node = new Node (Thread.currentThread(), mode); Node pred = tail; if ( pred != null ) { node.prev = pred; if (compareAndSetTail(pred, node)){ pred.next = node; return node; } } enq(node); return node; } private Node enq (final Node node) { for (;;){ Node t = tail; if (t == null ){ if (compareAndSetHead(new Node ())) tail = head; }else { node.prev = t; if (compareAndSetTail(t, node)){ t.next = node; return t; } } } } }
独占式同步状态获取与释放 独占式同步状态,是指在同一时刻只能有一个线程成功获取同步状态,锁的获取是排他的,不是共享的。
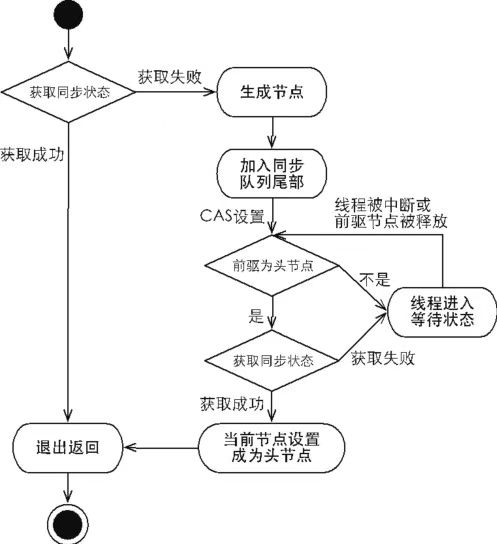
独占式同步状态获取流程如图所示:
相关的实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public final void acquire (int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } private final boolean acquireQueued (final Node node, int arg) { boolean failed = true ; try { boolean interrupted = false ; for (;;){ final Node p = node.predecessor(); if (p == head $$ tryAcquire (arg) ){ setHead(node); p.next = null ; failed = false ; return interrupted; } if (shouldParkAfterFailedAcquiredAcquire(p, node) && parkAndCheckInterrupe()) interrupted = true ; } }finally { if (failed) cancelAcquire(node); } }
独占式同步状态释放
1 2 3 4 5 6 7 8 9 10 public final void release (int arg) { if (tryRelease(arg)){ Node h = head; if (h != null && h.waitStatus != 0 ) unparkSuccessor(h); return true ; } return false ; }
共享式同步状态获取与释放 共享式获取与独占式获取最主要的区别在与同一时刻能否有多个线程同时获取到同步状态。以文件的读写为例,读操作可以是共享式访问,写操作则是独占式访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public final void acquireShared (int arg) { if (tryAcquireShared(arg) < 0 >) doAcquireShared(arg); } private void doAcquireShared (int arg) { final Node node = addWaiter(Node.SHARED); boolean failed = true ; try { boolean interrupted = false ; for (;;) { final Node p = node.predecessor(); if (p == head){ int r = tryAcquireShared(arg); if ( r >= 0 ){ setHeadAndPropagate(node, r); p.next = null ; if (interrupted) selfInterrupt(); failed = false ; return ; } } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true ; } } finally { if (failed) cancelAcquire(node); } } public final boolean releaseShared (int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true ; } return false ; }
独占式超时获取同步状态 超时获取同步状态,即在指定的时间段内获取同步状态,如果获取到同步状态则返回true,否则,返回false。具体流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private boolean doAcquireNanos (int arg, long nanosTimeout) throws InterruptedException{ long lastTime = System.nanoTime(); final Node node = addWaiter(Node,EXCLUSIVE); boolean failed = true ; try { for (;;){ final Node p = node.predecessor(); if (p == head && tryAcquire(arg)){ setHead(node); p.next = null ; failed = false ; return true ; } if (nanosTimeout <= 0 ) return false ; if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold) LockSupport.parkNanos(this nanosTimeout); long now = System.nanoTime(); nanosTimeout -= now - lastTime; lastTime = now; if (Thread.interrupted()) throw new InterruptedException (); } } finally { if (failed) cancelAcquire(node); } }
Condition实现细节 每个Condition对象都包含一个等待队列,Object包含一个AQS队列,两个队列节点是AQS中的Node,并用这个两个队列共同实现了wait/notify功能。
等待 Condition.await()让线程释放锁,构造新节点加入等待队列进入等待状态。返回的前提是重新获取了condition相关联的锁。底层是通过LockSupport的park()方法释放。
通知 Condition.signal()将等待队列中等待时间最长的节点加入同步队列,并用LockSupport.unpark()唤醒该节点。加入同步队列的节点通过tryAcquire()竞争获取锁,获取锁后从await()中返回继续执行。
并发集合实现细节 ConcurrentHashMap实现细节
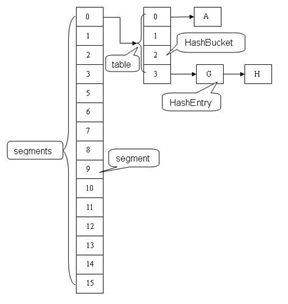
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
读取HashEntry信息是不需要拿锁,从而保证了并发读的高效性。HashMap中读取Map.Entry<K,V>是需要拿锁的。
1 2 3 4 5 6 static final class HashEntry <K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; }
在Hash中,会进行分段哈希从而保证segment中数组的均匀性,会对hash值的高字段和低字段进行分段处理,前半段获取segment位置,后端确定segment中数组中未知。
get()操作不需要枷锁,除非读到的值为空才会加锁重读。
put()操作需要对加锁操作。扩容时,只会对某segment中的数组进行扩种。
size()操作会两次不加锁计算,当操作数没有变化,则直接返回,如果变化则加锁获取size。
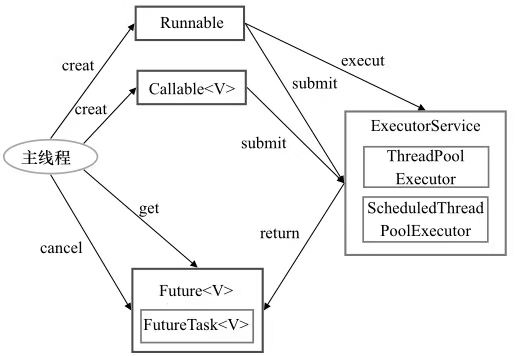
阻塞队列实现原理 线程池并行执行机制Executor Java线程即是工作单元,也是执行机制。工作单元包括Runnable和Callable,而执行机制由Executor框架提供。应用程序通过Executor框架控制上层的调度,下层的调度由操作系统内核控制,下层调度不受应用程序的控制。
Executor接收Runnable/Callable<T>接口的实例的任务,返回Future<T>接口的FutureTask<T>实例,当任务完成时,可以获取任务执行结果。
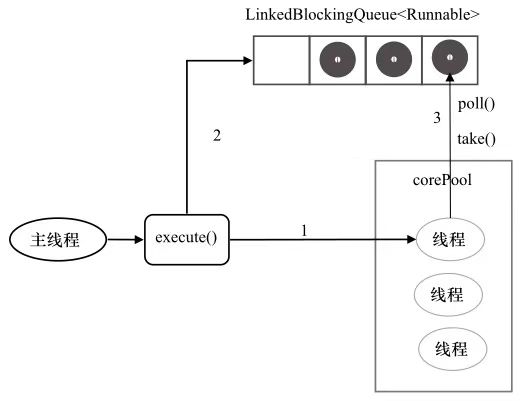
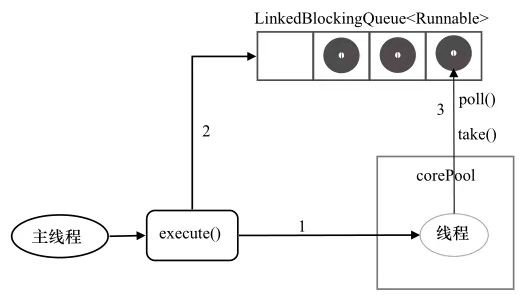
ThreadPoolExecutor (线程池)框架和实现原理 ThreadPoolExecutor可以有三种: FixedThreadPool, SingleThreadExecutor, CachedThreadPool。这三种是不同配置的ThreadPoolExecutor,并非不同子类型。
1 2 3 4 5 public static ExecutorService SingleThreadExecutor () { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>())); }; public static ExecutorService SingleThreadExecutor (ThreadFactory threadFactory) ;
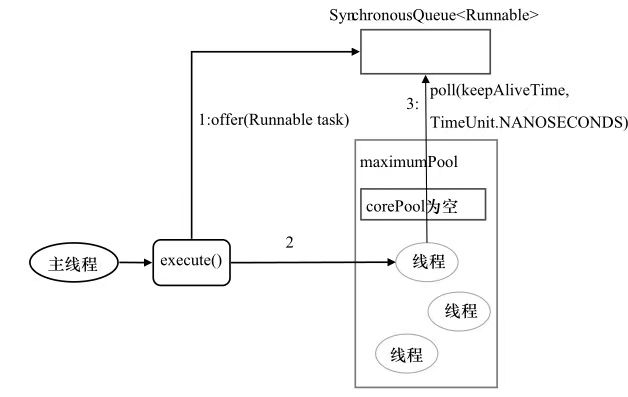
CachedThreadPool:
1 2 3 4 public static ExecutorService CachedThreadPool () { return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS,new SynchronousQueue <Runnable>()); }; public static ExecutorService CachedThreadPool (ThreadFactory threadFactory) ;
ThreadPoolExecutor实现原理 1 2 3 4 5 6 7 8 9 10 public Class ThreadPoolExecutor{ private int corePool; private int maximumPool; private BlockingQueue<Runnable> workQueue; private RejectedExecutionHandler handler; private long keepAliveTime; private TimeUnit unit; ... }
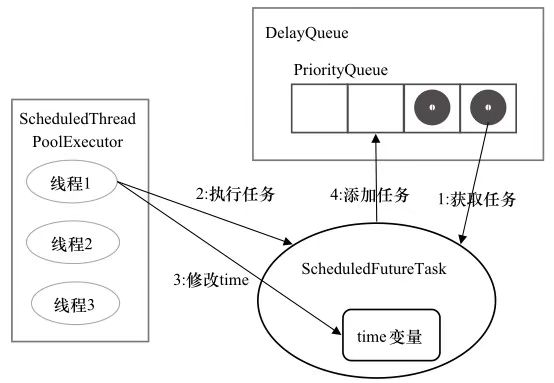
ScheduledThreadPoolExecutor (调度线程池)框架实现原理 调度线程池是线程池实现的扩展,主要在给定的延迟后运行任务,或者定期执行任务。
ScheduledThreadPoolExecutor:
1 2 public static ScheduledExecutorService newScheduledThreadPool (int corePoolSize) ;public static ScheduledExecutorService newScheduledThreadPool (int corePoolSize, ThreadFactory threadFactory) ;
SingleThreadScheduledExecutor:
1 2 public static ScheduledExecutorService SingleThreadScheduledExecutor () ;public static ScheduledExecutorService SingleThreadScheduledExecutor (ThreadFactory threadFactory) ;
ScheduledThreadPoolExecutor实现原理 1 2 3 4 5 public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor { private long time; private long sequenceNumber; private long period; }
提交任务DelayQueue<RunnableScheduledFuture>中。
执行任务
放回任务
DelayQueue部分实现原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class DelayQueue <E extends Delayed >{ private ReentrantLoc lock; private PriorityQueue<E> q; private Thread leader; private Condition available; public E take () { final ReentrantLock lock = this .lock; lock.lockInterruptibly(); try { for (;;){ E first = q.peek(); if ( first == null ) { available.await(); }else { long deplay = first.getDelay(TimeUnit.NANOSECONDS); if (delay > 0 ){ long tl = available.awaitNanos(delay); }else { E x = q.poll(); assert x != null ; if ( q.size() != 0 ) available.signalAll(); return x; } } } } finally { lock.unlock(); } } public void offer (E e) { final ReentrantLock lock = this .lock; lock.lock(); try { E first = q.peek(); q.offer(e); if (first == null ) || e.compareTo(first) < 0 ) available.singalAll(); return true ; } finally { lock.unlock(); } } }
ForkJoinPool 框架实现原理 ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,前者用于存放程序提交的任务,ForkJoinWorkerThread数组负责执行任务。
算法执行分两段,fork阶段将任务分割到足够小,创建/唤醒一个工作线程执行;join阶段将任务的结果收集合并结果得到最后的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class ForkJoinTask <V> { public final ForkJoinTask<V> fork () { ((ForkJoinWorkerThread) Thread.currentThread()).pushTask(this ); return this ; } public final V join () { if (doJoin() != NORMAL) return reportResult(); else return getRawResult(); } private V reportResult () { int s; Throwable ex; if ((s = status) == CANCELLED) throw new CancellationException (); if (s == EXCEPTIONAL && (ex = getThrowableException()) != null ) UNSAFE.throwException(ex); return getRawResult(); } private int doJoin () { Thread t; ForkJoinWorkerTHread w; int s; boolean completed; if ((t = Thread.currentThread()) instanceof ForkJoinWorkThread) { if (( s = STATUS) < 0 ) return s; if ( ((w = (ForkJoineWorkerThread)t).unpushTask(this ))) { try { completed = exec(); } catch (Throwable rex) { return setExceptionalCompletion( rex); } if (completed) return setCompletion(NORMAL); } return w.joinTask(this ); } else return exeternalAwaitDone(); } } public class ForkJoinWorkerThread { final void pushTask (ForkJoinTask<?> t) { ForkJoinTask<?>[] q; int s, m; if ((q = quque) != null ) { long u = (((s = queueTop) & (m = q.length - 1 )) << ASHIFT) + ABASE; UNSAFE.putOrderObject(q, u, t); queueTop = s + 1 ; if ((s -= queueBase) <= 2 ) pool.singalWork(); else if (s == m) growQuque(); } } }
异步执行机制 FutureTask实现原理 FutureTask实现了Future, Runnable接口。是Executor的执行任务单元,也可以由调用线程直接执行FutureTask.run()。FutureTask的get方法能阻塞当前线程,等待任务执行结果再执行下文。
FutureTask通过内部聚合的AQS的子类实现完成FUtureTask的获取和释放操作。队列中的每个FutureTask实例的get方法并不以一定需要在run方法之前执行,get方法会阻塞调用线程直到run方法被执行完成。每个任务只会执行一次,并且会有定义好的执行顺序,从get方法调用线程恢复执行上下文,从而达到异步调用的效果。类似.NET中的beginInvoke和endInvoke方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class FutureTask <V> implements Future <V>, Runnable{ private Sync sync; public void run () { ... Callable.call(); ... AQS.compareAndSetState(int expect, int update); ... AQS.releaseShared(int arg); ... FutureTask.done(); } public boolean cancel () ; public void get () { ... AQS.acquireSharedInterruptily(int arg); ... }; class Sync extends AbstractQueuedSynchronizer { public V innerGet () ; public void innerRun () ; public boolean innerCancel () ; } }
CompletableFuture实现原理 CompletableFuture实现了Future,CompletionStage接口,后者接口增加了更多对任务流程的控制接口,可以直接通过接口实现回调函数的定义。
从有限状态机机制理解Scheduler的实现原理