JVM memory management and GC
Java memory allocation
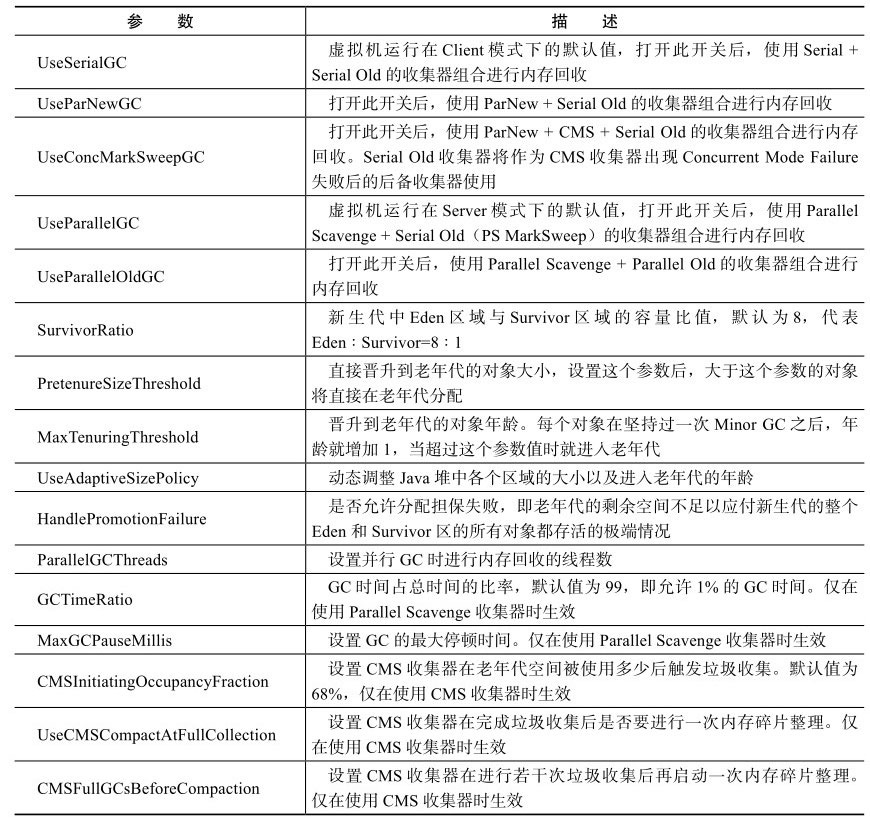
Java虚拟机管理内存会包括以下几个运行时数据区域,如下图所示。
JVM运行时数据区域简介
程序计数器(Program Counter Register)
程序计数器时当前线程执行字节码的行号指示器。每条线程有独立的程序计数器。
- 如果线程执行Java方法,这个技术及记录的时真该执行的虚拟机字节码指令的地址。
- 如果线程执行的时Native方法,这个计数器值则为Undefined。
Java虚拟机栈(JVM stacks)
JVM栈也是线程私有的。虚拟机栈描述的时Java方法执行的内存模型:
- 每个方法会先创建一个栈帧Stack Frame,用于存储局部变量表,操作数栈,动态链接,方法出口等信息。
- 在方法执行完后,该栈帧会出栈。
栈内存说的就是虚拟机中局部变量表部分。
Native方法栈
本地方法栈为虚拟机使用到的Native方法服务。
Java堆
Java堆是虚拟机所管理的内存,被所有线程共享的,目的是存放对象实例。Java堆是垃圾收集器(GC)主要管理的区域。
方法区
方法区是用于存储虚拟机的类信息,常量,静态变量,即时编译器编译后的代码等数据,被所有线程共享。在HotSpot虚拟机中,方法区又叫做“永久代”,是因为GC分代收集扩展至方法区,使得方法区由GC中的永久代区域实现。
运行时常量池
运行时常量池是方法区的一部分。本来在方法区中的类信息就包含了除类的版本、字段、方法、接口等描述信息之外,还有一项信息便是常量池,用于存放编译生成的各种字面量和符号引用。常量池信息将在类加载后进入方法区的运行时常量池中存放。同时,一些方法如String类的intern()方法也能将字符串加入运行时常量池。所以在类信息加载完成后,常量池也不是大小就不变的。
直接内存
直接内存并不是与JVM运行时数据区的一部分。JDK1.4后引入的NIO(New I/O)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式。它可以使用Native函数库直接分配对外内存,然后通过Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。直接内存不属于JVM GC的管理范畴,可以用-Xmx进行设定。
JVM对象的创建
当JVM遇到一条new指令时,会做出什么样的处理呢?
检查指令参数是否能在常量池中定位到一个类的符号引用,并确保其被正确的加载、解析和初始化;
在Java堆上分配内存,有两种空闲内存分配方式:
- 空闲列表: 基于Mark-Sweep算法的收集器的GC,如CMS;
- 指针碰撞: 具有compact过程的收集器的GC,如Serial, ParNew等。
为了避免竞争效应即操作的原子性,系统采用如下两种其一的方法:
- 分配内存动作进行同步处理,CAS(Compare and swap)+失败重试机制,
- 分配内存按照线程划分不同的空间之中进行,即本地线程缓冲机制(TLAB, Thread local allocation buffer)。
为新创建对象设置好初始值;
对对象的对象头信息(Object header)进行相关必要设置,如:
- 类型指向
- 类的元数据
- 对象哈希值
- 对象的GC年代信息
类文件bytecode中的< init>方法执行;
init方法是Java的class文件中的各种构造方法经过JIT解释后生成的bytecode代码,一般由invokespecial操作码所调用。
自此,一个完整的对象就被创建好了。
JVM对象的内存布局
当JVM对象被创建好了,会被分配在Java堆上,存储布局可以分为三个区域:对象头(header)、实例数据(instance data)和对齐填充(padding)。
对象头
对象头包括两部分,一部分是”Mark Word”,另一部分是类型指针。
- Mark word: 长度为32bit或64bit。HotSpot 32位虚拟机中具体的对象头存储内容取决于对象的锁状态值,如下:
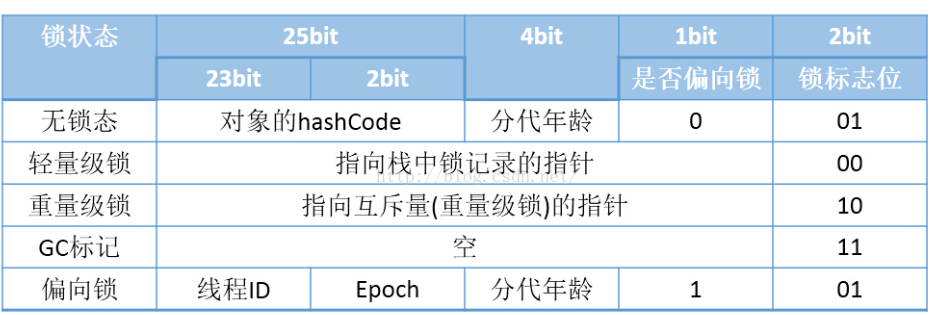
- 类型指针: 长度为32bit或64bit,用于存储指向类元数据的指针,并不是所有的虚拟机实现都必须在对象数据上保留类型指针。
- 数组长度:长度为32bit,当对象为数组时,用于存储数组的长度。注:此数组并非ArrayList泛型,后者属于引用类型。
实例数据
实例数据部分存储了类对象的所有类型的字段内容。每种虚拟机有自己定义好的参数和字段的分配策略。
对齐填充
对齐填充的存在是为了满足HotSpot VM自动内存管理系统要求,保证所有对象的地址都是8字节的整数倍。
Java基础类型内存布局
java的基本数据类型共有8种,即int,short,long,byte,float,double,boolean,char(注意,并没有String的基本类型)。Java基础类型变量是在(Java虚拟机)栈上分配的,当变量的作用域运行结束后,通过出栈的方式回收分配在栈上的变量内存。
当声明分配一个int类型变量a = 3时,JVM会先为该变量创建一个变量为a的引用,再在栈上搜索是否存在字面值为3的引用。
- 如果找到,就直接将a指向3的地址。
- 如果没有找到,就分配一个内存存放字面值3,并将a指向这个地址。
因此说,基础类型字面值在同一个栈上是共享的。
问题:已知int类型变量需要32bit内存,具体stack frame上内存分配是什么样子的呢? 变量a是怎么存放的? int类型信息又是放在那里的呢?
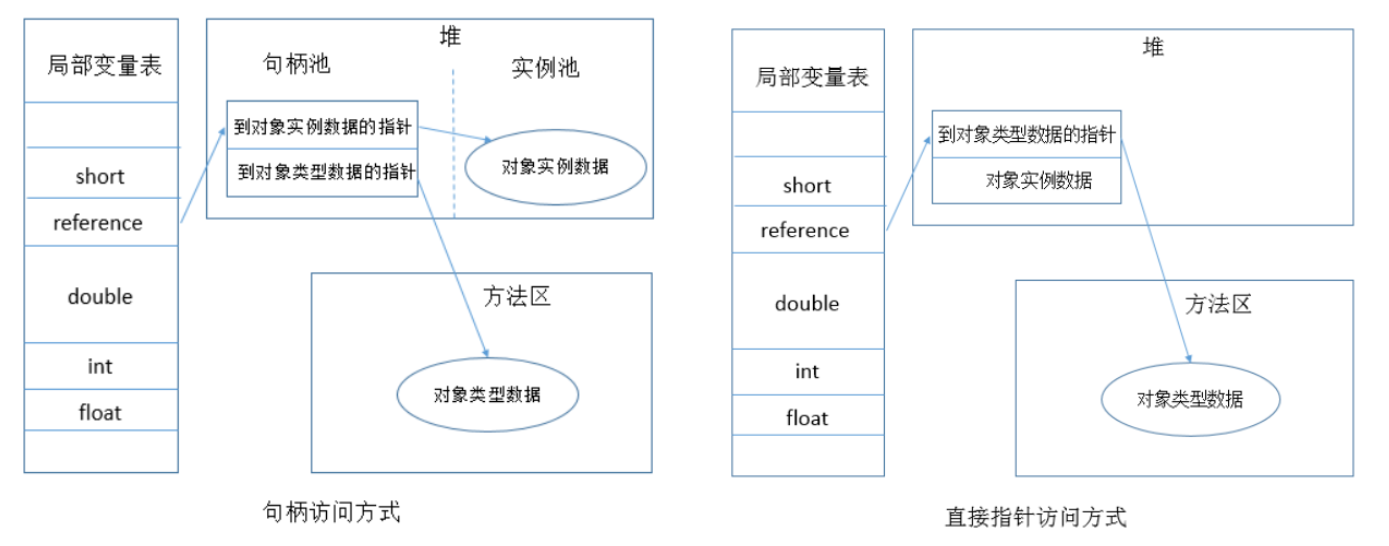
JVM对象的访问定位
对象的访问定位如下图,HOTSOPT用的是第2种算法:
- 使用句柄(先指向堆里的句柄池,再从句柄池找到指针,优点是只需要修改句柄, 缺点就是句柄池也是开销);
- 直接指针(减少性能开销): 需要存2个数据, 到对象实例数据的指针,到对象类数据的指针。
Garbage Collection of JVM
GC定义
Garbage Collection(垃圾回收/GC)是JVM对于Java堆上内存在运行时进行的动态管理,主要是对Java堆上不再被引用的对象进行回收。Minor GC是主要快速回收Eden区和Survivor区对象内存,Full GC则会对老年代也进行回收,后者可能会影响性能。
如何确定对象是否需要回收?
引用计数算法(Reference Counting)
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
缺点:存在循环引用的问题。
可达性分析算法(Reachability Analysis)
通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。
GC Roots:
- 虚拟机栈中引用的对象
- 方法去中类静态属性引用的对象
- 方法去中常量引用的对象
- 本地方法栈中JNI(Native方法)引用的对象。
如何对对象进行回收?
标记——清除算法
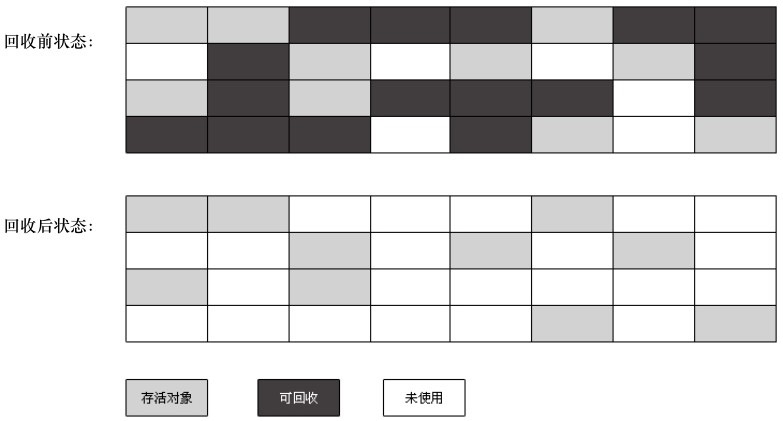
复制算法
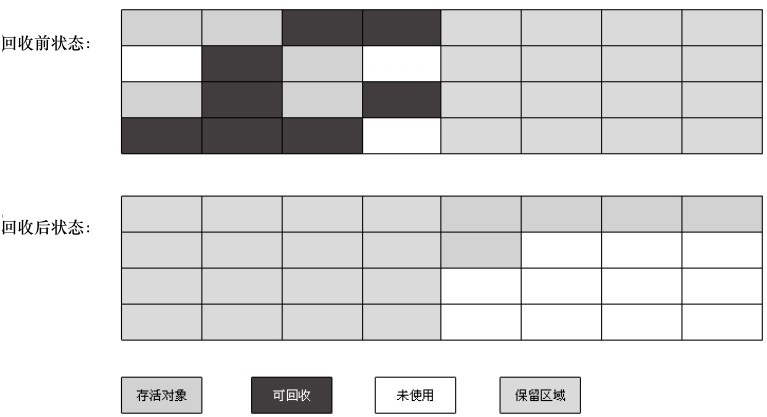
标记——整理算法
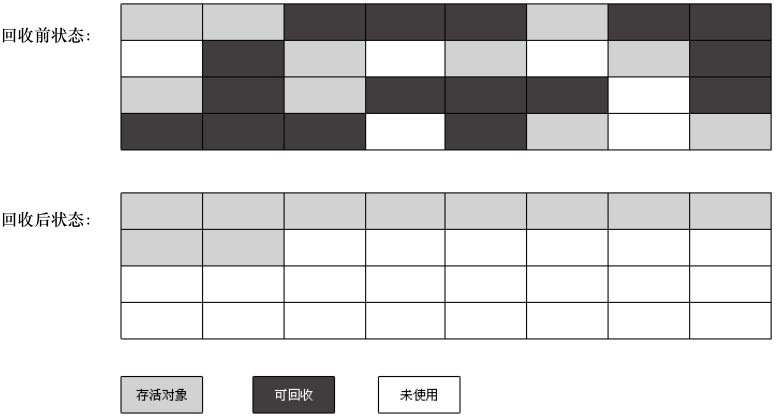
分代收集算法
对于新生代和老年代的对象进行不同的清理算法,一般来说,复制算法适合新生代,标记-清除算法和标记整理算法更适合老年代内存。
JVM对象内存管理策略
GC管理的内存分为三类区域,分别是Eden+Survivor(新生代),Tenured(老年代)和Permanent(永久代)。
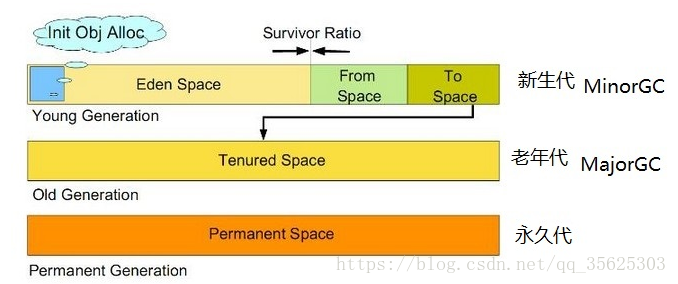
对象优先在Eden分配
大对象直接进入老年代
长期存活的对象将进入老年代
动态对象年龄判定:当Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或者等于该年龄的对象可以直接进入老年代,无须等到MaxTenuringThreshold中要求的年龄。这是为了防止Survivor区溢出。
JVM常用的垃圾收集器
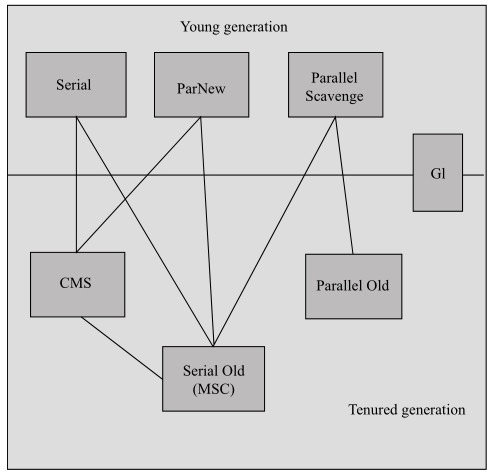
Serial收集器
单线程处理新生代GC。复制算法。STW

ParNew收集器
采用多线程处理新生代GC。复制算法。STW

Parallel Scavenge收集器
处理算法和ParNewGC完全一样。
但是,Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量(Throughput)。所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 /(运行用户代码时间 +垃圾收集时间),虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
Serial Old收集器
单线程处理老年代GC。采用标记-整理算法。STW
Parallel Old收集器
多线程处理老年代GC。采用标记整理算法。STW
CMS(Concurrent Mark Sweep)收集器
四个阶段(基于标记-清理算法):
- 初始标记 STW
- 并发标记
- 再次标记 STW
- 并发清理

问题:
- 并发清理时预留空间不够造成并发清理(Concurrent Mode Failure)失败=>浮动垃圾(Floating Gabage)过多。
- 内存碎片化问题。一旦发生大对象触发的FullGC,Serial Old回收则会出现长时间STW。
CMS并发三色标记法
- 黑色:已经标记完引用对象的颜色
- 灰色:没有标记完引用对象的颜色
- 白色:默认垃圾(没有被标记颜色)
标记问题:
- 本来A->B, B->D;
- 在A标记完,B部分标记后,B->D引用消失,D没有被标记,A->D引用建立
- 由于D从始至终都没有被标记
标记问题一Incremental Update更正:
- 对于A->D(白)的引用建立,把A修正成灰色。
Incremental Update更正存在的ABA问题:
- 回收线程一:标记A属性1,正在标记属性2
- 业务逻辑线程二:把属性1指向白色D, A保持灰色
- 回收线程三: 更新属性2的标记,将A标记为黑色
CMS最终解决方案:必须STW从头扫描一次
G1(Garbage First)收集器
启动G1需要参数-XX:+UseG1GC,G1不是与其他GC分代处理垃圾的,而是对新生代和老年代均进行不同的GC。
Young GC:
- 标记-清除-复制算法整理 STW
只对新生代区块进行清理,但是也会需要扫描所有region的Rset,否则不知道有哪些Old->Young的引用。
Mixed GC:
处理Mixed GC时只将将部分old区块进行回收。Rset记录了其他区块对本区块的引用。最终的扫描区域为Young+对Rset进行扫描,缩短了原来需要扫描整个Old时间。而且Young<->Old的引用都能快速找到。
并发标记分为四个阶段(基于标记-整理算法):
- 初始标记 STW
- 并发标记
- 最终标记 STW
- 筛选回收 STW 根据停顿时间要求筛选出Old中的Cset集合,作为回收目标。
回收evacuation阶段(小区块进行复制整理避免碎片):
需要STW,将选出的Cset中的对象进行复制到新的区块,清除掉原来的区块,达到收集的效果。

ZGC(Z Garbage Collector)收集器
ZGC(Z Garbage Collector)是一款由Oracle公司研发的,以低延迟为首要目标的一款垃圾收集器。它是基于动态Region内存布局,(暂时)不设年龄分代,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-整理算法的收集器。在JDK 11新加入,还在实验阶段,主要特点是:回收TB级内存(最大4T),停顿时间不超过10ms。m目前ZGC是实验性功能,可以通过-XX:+UnlockExperimentalVMOptions -XX:+UseZGC参数启动ZGC。
垃圾收集器参数